Как создать предметно-ориентированную вопрос-ответную модель
На сегодняшний день продвинутые разговорные модели так или иначе используют большие языковые модели (LLM), такие, как ChatGPT, Yandex GPT, GigaChat и др. Такие модели обучены на огромных массивах данных, они способны отлично поддерживать диалог на общие темы. Однако на практике часто встречаются задачи, когда нам хочется создать диалоговую модель, способную беседовать на какие-то конкретные темы - например, отвечать на вопросы про продукты компании, или рекомендовать, где купить лекарство в соответствии и текущими данными о доступности из базы данных.
Такие чат-боты могут быть реализованы двумя путями:
- До-обучение разговорной модели подразумевает fine-tuning существующей языковой модели на корпусе текстов, либо на специально подготовленных вопрос-ответных парах. На русском языке есть семейство сравнительно небольших моделей ruGPT, которые можно доучить на одном большом GPU типа A100. В любом случае, доучивание требует значительных вычислительных мощностей, усилий и опыта, и при этом любые изменения в предметной области требуют повторного обучения модели. Представьте ситуацию, когда мы реализовали таким образом консультанта для банка, а затем изменилась процентная ставка по вкладам - этот факт нельзя будет легко интегрировать в модель без повторного обучения.
- Retrieval-Augmented Generation - это подход, при котором ответ чат-бота формируется стандартной предобученной LLM-моделью, но предварительно ей показывают фрагменты текста из предметно-ориентированной базы знаний, найденные с помощью семантического поиска. В таком случае LLM используется в режиме продвинутого перефразировщика и извлечения ответа на вопрос из текста. Такой подход по сути похож на ранее популярный Open Domain Question Answering, используемый совместно с моделями типа BERT.
В данной статье мы рассмотрим создание вопрос-ответного чат-бота с помощью второго подхода с использованием фреймворка LangChain и языковой модели Yandex GPT. В качестве исходного материала для создания чат-бота мы используем набор видео-файлов - это позволит нам также продемонстрировать асинхронное распознавание речи на основе Yandex SpeechKit для преобразования звуковой дорожки видео в текстовый корпус.
Данная статья представляет собой описание первой части мастер-класса, проводимого на конференции Practical ML Conf. Весь код мастер-класса доступен на GitHub.
Описанные в этой статье операции лучше проводить с помощью Yandex DataSphere, поскольку она обеспечивает удобную интеграцию с другими сервисами Yandex Cloud, например, объектным хранилищем S3 (которое, в свою очередь, нужно для асинхронного распозавания речи). Но теоретически Вы можете воспользоваться и другими инструментами.
Как работает Retrieval-Augmented Generation
Представим себе, что мы хотим использовать большую языковую модель в качестве ассистента или умного чат-бота. В простейшем случае, для получения более-менее соответствующих по стилю ответов, используют Prompt Engineering, т.е. модифицируют исходный запрос, или предваряют его набором специфичных инструкций, например:
Представь себе, что ты ассистент в магазине электроники
по имени Вася, и тебе нужно ответить на запросы покупателей
про различные модели техники. Ответь на вопрос ниже по
возможности подробно:
[question]
Чем iPhone лучше Андроида?
[/question]
Такую схему можно представить себе следующим образом:

В случае с Retrieval-Augmented Generation, мы имеем некоторую базу знаний, состоящую из небольших, но осмысленных фрагментов текста - обычно, около 1024 токенов. По полученному от пользователя запросу мы ищем наиболее релевантные фрагменты текста - например, 3 или 5 самых подходящих - и затем просим языковую модель ответить на вопрос, посмотрев на найденные фрагменты текста:
Представь себе, что ты ассистент в магазине электроники
по имени Вася, и тебе нужно ответить на запросы покупателей
про различные модели техники. Прочитай текст в тегах info и
ответь на вопрос в тегах question по возможности подробно. Если
явный ответ не содержится в тексте, не пытайся его придумать.
[info]
Ведущее издание электроники пишет, что iPhone обгоняет своих
конкурентов по качеству камеры. Кроме того, ...
[/info]
[question]
Чем iPhone лучше Андроида?
[/question]
Этот процесс можно наглядно изобразить на такой схеме:
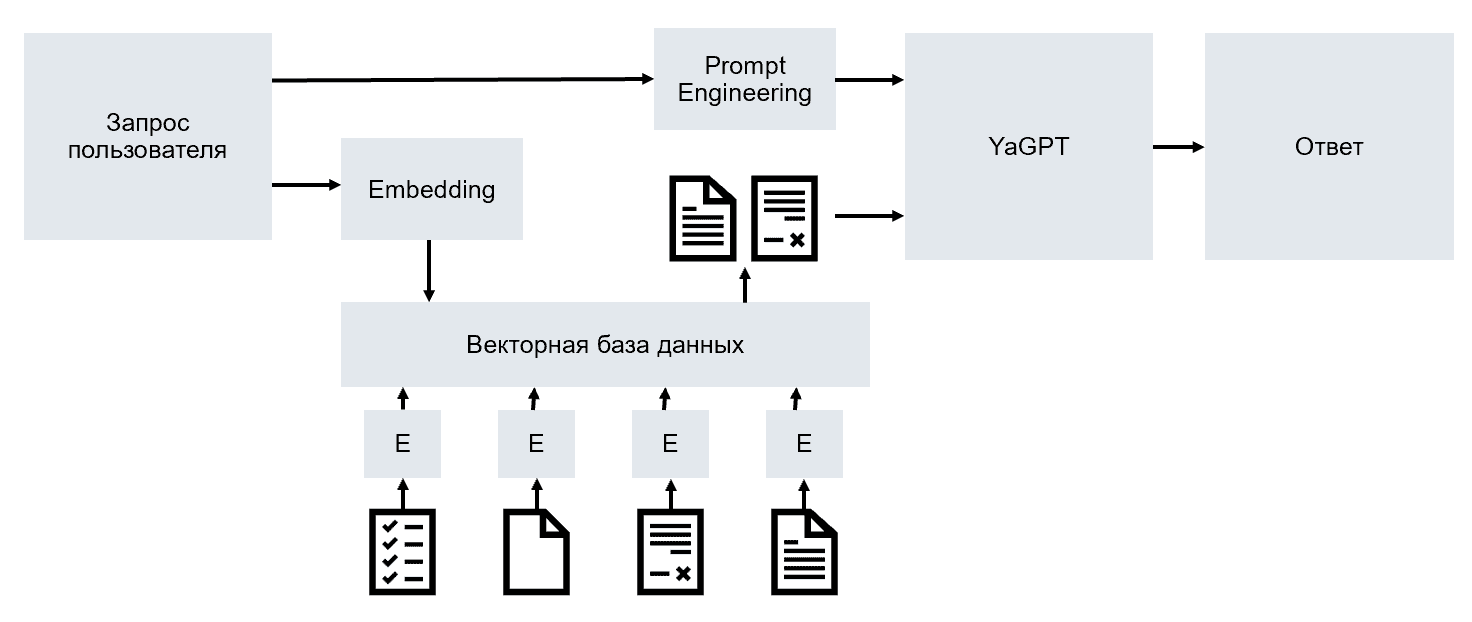
Остаётся открытым вопрос, как организовать умный поиск по коллекции документов, который был бы лучше, чем просто полнотекстовый поиск, а учитывал бы смысл. Для этого используется понятие текстовых эмбеддингов - способа сформировать по фрагменту текста некоторый смысловой вектор таким образом, что для близких по смыслу фрагментов текста вектора также будут близки в смысле некоторой метрики.
Таким образом, нам будет необходимо посчитать эмбеддинги для всех фрагментов текста (это можно сделать один раз при начальном индексировании), а затем для запроса, и найти ближайшие по расстоянию вектора - им и будут соответствовать наиболее близкие по смыслу фрагменты текста.
Для хранения векторов и быстрого поиска по ним, используют специальные базы данных - векторные базы данных. Таким образом, специализированный вопрос-ответный чат-бот будет включать в себя средства вычисления эмбеддингов, векторную базу данных содержимого, большую языковую модель и средства промпт-инжиниринга. Все эти составляющие удобным образом содержатся в библиотеке LangChain, которая в последнее время стремительно набирает популярность.
Ниже я расскажу, как собрать вопрос-ответного бота на LangChain на основе набора видео-файлов.
Преобразуем видео в текст
Для начала, нам нужно собрать текстовый корпус, содержащий информацию из интересующей нас предметной области. В качестве исходных данных мы возьмём несколько видео с YouTube, например, обзоров различной техники от Wylsacom.

Нам будет достаточно собрать ссылки на видео:
videos = ['https://www.youtube.com/watch?v=QuSz0FAvNrE',
# здесь могут быть другие видео
'https://www.youtube.com/watch?v=3ucnBEkVuKc'
]
Чтобы скачать аудио-дорожки к этим видео, используем библиотеку pytube:
for i,url in enumerate(videos):
yt = YouTube(url)
print(f"Downloading {yt.title}")
yt.streams.filter(mime_type="audio/webm").first().download(
output_path="./audio",filename=f"{i}.opus")
В результате в директории audio у нас окажутся пронумерованные аудиофайлы в формате opus.
Прежде, чем приступать к распознаванию, необходимо преобразовать их к формату, который будет понимать Yandex SpeechKit. Для этого можно использовать библиотеку librosa:
import glob
import librosa
import soundfile as sf
target_sr = 8000
for fn in glob.glob("./audio/*.opus"):
print(f"Processing {fn}")
au,sr = librosa.load(fn,sr=target_sr)
sf.write(fn.replace('.opus','.ogg'),au,
target_sr,format='ogg',subtype='opus')
В результате получаем набор файлов с расширением ogg, которые можно подавать на вход Yandex Speechkit. Поскольку речь идёт о распознавании большого объема текста, будем использовать асинхронное распознавание (транскрибацию): для этого необходимо положить все файлы в хранилище S3, запустить процесс распознавания, и затем периодически проверять результаты.
При использовании DataSphere, скопировать файлы в S3 проще всего, подключив некоторое хранилище к DataSphere через S3-коннектор. Предположим, мы смонтировали бакет mclass в директорию mclass, в этом случае файлы можно переместить простым копированием:
!mkdir -p /home/jupyter/mnt/s3/mclass/audio
!cp ./audio/*.ogg /home/jupyter/mnt/s3/mclass/audio
Для запуска распознавания опишем функцию submit_for_sr, которая будет формировать запрос в соответствии с этим API:
def submit_for_sr(audio_file):
j = { "config": {
"specification": { "languageCode": "ru-RU" }},
"audio": { "uri": audio_file }}
res = requests.post(
"https://transcribe.api.cloud.yandex.net/speech/stt/v2/longRunningRecognize",
json = j,
headers = { "Authorization" : f"Api-Key {api_key}" })
return res.json()['id']
При этом для работы этой функции нам надо будет создать в нашем облаке сервисный аккаунт, имеющий доступ к функции распознавания речи, чтения хранилища и работы с языковыми моделями, и создать ключ API для этого аккаунта. Предполагается, что переменная api_key содержит этот ключ.
Для посылки всех файлов на распознавание, используем обычный цикл:
d = {}
for fn in glob.glob('/home/jupyter/mnt/s3/mclass/audio/*.ogg'):
ext_name = fn.replace('/home/jupyter/mnt/s3/',
'https://storage.yandexcloud.net/')
id = submit_for_sr(ext_name)
print(f"Submitted {fn} -> {id}")
d[id] = fn
В этом коде с помощью replace мы заменяем локальный путь к файлу на URL-ссылку на файл в хранилище S3. Хранилище при этом не должно быть открыто для чтения - нужный доступ будет автоматически предоставлен соответствующему сервисному аккаунту.
В результате, в словаре d окажутся списки идентификаторов процессов распознавания, и соответствующие пути файлов. Чтобы проверить готовность распознавания, определим такую функцию:
def check_ready(id):
res = requests.get(f"https://operation.api.cloud.yandex.net/operations/{id}",
headers = { "Authorization" : f"Api-Key {api_key}" })
res = res.json()
if res['done']:
return res['response']
else:
return None
Пока результат не готов, эта функция будет возвращать None, а после готовности вернёт JSON-файл с распознанными фрагментами.
Теперь реализуем код, который проверяет все распознавания на готовность, а в случае готовности помещает результат в словарь txt:
txt = {}
while True:
for k,v in d.items():
if v in txt.keys():
continue
res = check_ready(k)
if res is None:
print(f"{k} -> waiting")
else:
print(f"{k} -> ready")
txt[v] = ' '.join([x['alternatives'][0]['text']
for x in res['chunks']])
if len(txt.keys())==len(d.keys()):
break
time.sleep(10)
Когда все результаты получены, нам осталось лишь сохранить текстовые файлы:
for k,v in txt.items():
with open(k.replace('.ogg','.txt')
.replace('/audio/','/text/'),
'w',encoding='utf-8') as f:
f.write(v)
Разбиваем текст на фрагменты
На предыдущем этапе, мы получили набор текстовых файлов, по одному на видео. Однако, они скорее всего слишком велики, чтобы быть использованными для запросов. Дело в том, что у нас есть два ограничения:
- Размер контекста эмбеддинга показывает, сколько токенов мы можем использовать для вычисления смыслового вектора. Обычно, размер контекста эмбеддинга не слишком велик - от 512 токенов, до 2048.
Токен - это единица входного текста, подающаяся на вход нейросетевой модели. Обычно, токеном является слово, или чаще часть слова. Например, в модели Yandex GPT длина одного токена обычно составляет около 3 символов.
- Размер контекста языковой модели, т.е. насколько длинным может быть запрос (или запрос+ответ). Для Yandex GPT длина контекста запроса+ответа составляет чуть более 7000 токенов, и в эти токены должны входить 3-5 лучших найденных фрагментов текста, сам запрос с инструкциями, и выдаваемый пользователю ответ.
Исходя из этих соображений, длина фрагмента текста обычно выбирается 512-2048 токенов. Иногда проще задавать эту длину в символах, поскольку не всегда заранее очевидно, как будет токенизирован текст.
import langchain
import langchain.document_loaders
source_dir = "/home/jupyter/mnt/s3/mclass/text"
loader = langchain.document_loaders.DirectoryLoader(
source_dir,glob="*.txt",
show_progress=True,recursive=True)
splitter = langchain.text_splitter.RecursiveCharacterTextSplitter(
chunk_size=1024,chunk_overlap=128)
fragments = splitter.create_documents(
[ x.page_content for x in loader.load() ])
В данном случае мы используем удобный класс RecursiveCharacterTextSplitter, который сначала пытается разбить текст по большим разделителям (абзацам), потом - по разделителям между предложениями, и в худшем случае использует разделители между словами. Это позволяет получить наиболее осмысленные фрагменты текста.
В результате у нас получится переменная fragments, содержащая фрагменты текста.
В реальных проектах, при индексировании большого объема документов, не стоит рассчитывать на то, что они все поместятся в память. В этом случае разбиение на фрагменты нужно совмещать с помещением фрагментов в векторную базу данных, которая хранится на диске.
Вычисляем эмбеддинги
Вычисление эмбеддингов - это достаточно важная задачи, и подобрать оптимальный вариант для русского языка непросто. LangChain содержит много готовых классов, которые позволяют вычислять эмбеддинги как локально с помощью предобученных (или даже обученных вами) моделей, так и с помощью онлайн-сервисов, таких, как OpenAI.
Я остановлюсь на двух вариантах вычисления эмбеддингов:
- Использовать какую-нибудь модель с HuggingFace с поддержкой русского языка. LangChain позволяет вычислять эмбеддинги с помощью HuggingFace-моделей в пару строк кода. Размер контекста такой модели как правило не очень велик, поэтому нужно будет соответствующим образом подобрать
chunk_size в коде выше при разбиении текста
embeddings = langchain.embeddings.HuggingFaceEmbedding(
model_name="distiluse-base-multilingual-cased-v1")
sample_vec = embeddings.embed_query("Hello, world!")
from langchain.embeddings.base import Embeddings
import time
class YaGPTEmbeddings(Embeddings):
def __init__(self,folder_id,api_key,sleep_interval=1):
self.folder_id = folder_id
self.api_key = api_key
self.sleep_interval = sleep_interval
self.headers = {
"Authorization" : f"Api-key {api_key}",
"x-folder-id" : folder_id }
def embed_document(self, text):
j = {
"model" : "general:embedding",
"embedding_type" : "EMBEDDING_TYPE_DOCUMENT",
"text": text
}
res = requests.post(
"https://llm.api.cloud.yandex.net/llm/v1alpha/embedding",
json=j,headers=self.headers)
vec = res.json()['embedding']
return vec
def embed_documents(self, texts, chunk_size = 0):
res = []
for x in texts:
res.append(self.embed_document(x))
time.sleep(self.sleep_interval)
return res
def embed_query(self, text):
j = {
"model" : "general:embedding",
"embedding_type" : "EMBEDDING_TYPE_QUERY",
"text": text
}
res = requests.post(
"https://llm.api.cloud.yandex.net/llm/v1alpha/embedding",
json=j,headers=self.headers)
vec = res.json()['embedding']
return vec
embeddings = YaGPTEmbeddings(folder_id,api_key)
res = embeddings.embed_documents(['Hello','there'])
Обновление от октября 2023: Вместо того, чтобы самим реализовывать класс для вычисления эмбеддингов, можно воспользоваться библиотекой yandex-chain, которая содержит более надёжную реализацию, чем приведённая выше.
Этот класс содержит два основных метода, каждый из которых вызывает соответствующее API Yandex Cloud:
embed_query используется для вычисления эмбеддинга запросаembed_documents используется для вычисления эмбеддинга семейства документов. Поскольку Yandex API поддерживает вычисление эмбеддинга только для одного документа за вызов, то этот метод реализован как цикл, вызывающий метод embed_document для каждого документа в коллекции.
Поскольку в настоящее время доступ к сервису лимитирован 1 запросом в секунду, между вызовами добавлена задержка.
В следующем разделе нам понадобится вычислять эмбеддинги. Для этого используем переменную embeddings - вы можете использовать один из двух предложенных выше вариантов на выбор.
Сохраняем документы в векторную БД
LangChain поддерживает множество векторных БД, от очень простой и легковесной ChromaDB, до большого решения на кластере OpenSearch. Выбирать решение можно исходя из сложности задачи и объема данных.
Если Вы строите решение в облаке Yandex Cloud, то можно использовать управляемый OpenSearch в Yandex Cloud - это упростит управление, и позволит отдать масштабирование на откуп облачным сервисам.
В нашем примере мы используем LanceDB, поскольку она позволяет сохранять базу данных в обычной директории. Для начала создадим таблицу:
from langchain.vectorstores import LanceDB
import lancedb
db_dir = "../store"
db = lancedb.connect(db_dir)
table = db.create_table(
"vector_index",
data=[{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}],
mode="overwrite")
Чтобы проиндексировать все документы, используем возможности LangChain:
db = LanceDB.from_documents(fragments, embeddings, connection=table)
Теперь, чтобы найти ближайшие по расстоянию документы, можно использовать метод similarity_search:
q="Чем iPhone лучше Samsung?"
res = db.similarity_search(q)
for x in res:
print('-'*40)
print(x.page_content)
Можно также использовать интерфейс retriever, позволяющий задать различные стратегии и параметры поиска, например:
retriever = db.as_retriever(
search_kwargs={"k": 5})
res = retriever.get_relevant_documents(q)
Учимся работать с Yandex GPT
Также как и в случае с эмбеддингами, LangChain не содержит встроенных инструментов работы с генеративной языковой моделью Yandex GPT. Поэтому нам нужно будет реализовать адаптер самостоятельно, в соответствии с документацией:
class YandexLLM(langchain.llms.base.LLM):
api_key: str = None
folder_id: str
max_tokens : int = 1500
temperature : float = 1
instruction_text : str = None
def _call(self, prompt) :
headers = {
"x-folder-id" : self.folder_id ,
"Authorization" : f"Api-key {self.api_key}"}
req = {
"model": "general",
"instruction_text": self.instruction_text,
"request_text": prompt,
"generation_options": {
"max_tokens": self.max_tokens,
"temperature": self.temperature
}
}
res = requests.post(
"https://llm.api.cloud.yandex.net/llm/v1alpha/instruct",
headers=headers, json=req).json()
return res['result']['alternatives'][0]['text']
Этот код для ясности немного упрощен, более полная версия содержится в репозитории GitHub
Обновление от октября 2023: Вместо того, чтобы самим реализовывать класс YandexLLM, можно воспользоваться библиотекой yandex-chain, которая содержит более надёжную реализацию, чем приведённая выше. Кроме того, поддержка Yandex GPT есть в библиотеке GigaChain, реализации LangChain от Сбер.
Теперь мы можем работать с моделью следующим образом:
instructions = """
Представь себе, что ты технический блоггер, который делает обзоры
современной электроники. Тебя спрашивает знакомый. Постарайся
ответить на его вопрос подробно и доступно."""
llm = YandexLLM(api_key=api_key, folder_id=folder_id,
instruction_text = instructions)
llm(q)
Если мы зададим вопрос про то, чем iPhone лучше Samsung, то можем получить примерно такой ответ:
Приветствую! Сегодня я хочу сравнить два популярных смартфона - iPhone и Samsung. Оба варианта имеют свои преимущества и недостатки.
Начнем с дизайна. В отличие от многих Samsung, называемых “кирпичами”, комбинация материалов iPhone создает ощущение минималистичности и элегантности. Кроме того, iPhone преданы монобровь, функция Raise to wake, чтобы вы могли насладиться полноэкранным просмотром видео или изображений без черных платаповков во время эксплуатации, удобен в использовании, является универсальным (работает все известные Приложения)
Дизайн Samsung Galaxy имеет высоко-концентрированный документ Center Wheel и Trade приложение для переднего управления, которое удобно используется для определения яркости, открытия приложения многозадачности. Он также имеет встроенную камеру со множеством эффектов снимков, которые забавляют для вас. К этим изменениям можно добавить датчик шагового.
Реализуем Retrieval-Augmented Generation
В коде выше мы уже нашли 5 наиболее подходящих фрагментов текста для нашего запроса q, и они находятся в переменной res. Каждый документ имеет поле page_content с текстом страницы.
Retrieval-Augmented Generation можно реализовать с помощью механизма цепочек (chain) и метода StuffDocumentsChain, который делает следующее:
- Берёт коллекцию документов input_documents
- Каждый из них пропускает через некоторый шаблон
document_prompt, и затем объединяет вместе. - Данный текст помещается в переменную
document_variable_name и передаётся большой языковой модели llm
В нашем случае document_prompt не будет модифицировать документ, а будет просто возвращать его без изменений:
# Промпт для обработки документов
document_prompt = langchain.prompts.PromptTemplate(
input_variables=["page_content"], template="{page_content}")
Для формирования окончательного ответа мы используем более сложный шаблон, который принимает на вход пользовательский запрос query и контекст context (это как раз найденные наиболее релевантные фрагменты текста):
# Промпт для языковой модели
document_variable_name = "context"
template = """
Пожалуйста, посмотри на текст ниже и ответь на вопрос, используя
информацию из этого текста.
Текст:
-----
{context}
-----
Вопрос:
{query}"""
prompt = langchain.prompts.PromptTemplate(
template=template, input_variables=["context", "query"])
Далее мы создаём цепочку llm_chain, которая вызывает описанную нами ранее языковую модель Yandex GPT llm с шаблоном prompt, после чего инициализируем основную цепочку chain
# Создаём цепочку
llm_chain = langchain.chains.LLMChain(llm=llm, prompt=prompt)
chain = langchain.chains.StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt,
document_variable_name=document_variable_name)
Теперь, чтобы получить ответ на запрос q с коллекцией документов res, мы просто запускаем цепочку:
chain.run(input_documents=res, query=q)
Вот полученный в моём случае ответ:
Если вы хотите продать свой смартфон через продолжительное время в будущем, я бы рекомендовал инвестировать в Apple, потому что после выпуска недавно нового iphone SE - они все еще способны обеспечивать достойную стоимость устройств по прошествии времени. Кроме того, смартфоны apple показывают большую стабильность в основных системах и приложениях. Несмотря на эти ограничения, возможность обновления devices со временем может быть стимулом для тех, кто ищет долгосрочную инвестиционную цель для своих устройств.
Если ценность телефона является ключевым фактором, я бы порекомендовал рассматривать модели с лучшими ЖК-дисплеями в вашем бюджете, чтобы рассмотреть долгосрочный обмен. Samsung все еще остается лидером в производстве дисплеев, особенно в их линейке galaxy S.
Также я бы обращал внимание на программное обеспечение iOS, которое предоставляет множество дополнительных возможностей, хотя отсутствие обновления могла бы смутить некоторых пользователей.
Субъективно кажется, что этот ответ существенно более глубокий, вероятно из-за того, что он учитывает высказанные Wylsacom экспертные замечания.
Преобразование контекста
Теперь нам осталось собрать всё вместе и реализовать одну функцию answer, которая будет отвечать на вопрос пользователя.
Однако, добавим ещё один небольшой финальный штрих - это изменение порядка фрагментов в контексте. Дело в том, что часто языковые модели устроены таким образом, что максимально значимыми фрагментами запроса является его начало и конец, в связи с чем логичнее располагать более релевантные фрагменты текста ближе к началу и концу запроса. Класс LongContextReorder позволяет нам легко реализовать такое перемешивание найденных фрагментов текста.
С учётом сказанного, функция answer будет выглядеть так:
from langchain.document_transformers import LongContextReorder
reorderer = LongContextReorder()
def answer(query,reorder=True):
results = retriever.get_relevant_documents(query)
if reorder:
results = reorderer.transform_documents(results)
return chain.run(input_documents=results, query=query)
Также мы можем реализовать функцию для сравнения ответов “голой” языковой модели, и нашего бота с Retrieval-Augmented Generation:
def compare(q):
print(f"Ответ YaGPT: {llm(q)}")
print(f"Ответ бота: {answer(q)}")
compare("Какой макбук лучше выбрать студенту?")
Смотрите на результаты:
| Yandex GPT | Наш бот |
| Выбор Макбука для студента зависит от нескольких факторов, таких как бюджет, требования к производительности и задачам, которые предстоит решать в университете. Важно учитывать технические характеристики, такие как процессор, оперативная память, жесткий диск, а также другие особенности, такие как размер экрана, графика и другие. Если студенты ищут недорогое устройство, то Apple Macbook Air может быть хорошим выбором. Он имеет легкий корпус, маленький экран и низкое электропотребление, что позволяет использовать его в дороге с легкостью. Однако, если нужен более мощный ноутбук для рабочих задач, тогда стоит рассмотреть Macbook Pro. У него более производительный процессор и большой объем оперативной памяти, что позволит выполнять сложные задачи без задержек. Также стоит учитывать, что экран у Macbook Pro больше и разрешение выше, что делает работу более комфортной. Наконец, если необходимо иметь ноутбук с возможностью расширения оперативной памяти и хранения данных, следует обратить внимание на Macbook Pro с дополнительным слотом для расширения. Это обеспечивает дополнительные возможности для производительности при работе с требовательными приложениями. | Как технический блогер, специализирующийся на обзорах современной электроники, скажу, что для студента лучше выбирать между MacBook Air 13” M1 и MacBook Pro 13” M2. Если рассматривать первый вариант, то он будет отличным выбором для студентов, так как он имеет стильный дизайн, хорошее качество сборки, быстрый процессор M1, достаточный объем встроенной памяти и быстрый SSD-диск. Так же в сравнение с другими ноутбуками этого же класса он выигрывает по результатам бенчмарков и тестов на скорость работы. Из минусов — несколько устаревший дизайн ноутбука в сравнении с более новыми моделями и отсутствие встроенного WIFI 6. Кроме того, немного смущает цена этого ноутбука. Однако он является идеальным ноутбуком для учебы и работы. К тому же, этот ноутбук легче своего предыдущего варианта — MacBook Air на процессоре Intel, что делает его хорошим выбором для мобильного использования. Один из главных вариантов такой организации учебного процесса в вузах – это дистанционное образование. Хотя карантинная ситуация всё еще остается в центре внимания многих людей, а школы вынужденно переходят на дистанционное обучение, университеты тоже старались максимально ускорить переход своих студентов на удаленную учебную систему. Средний студент легко приобретает специальный деcктоп или ноутбук, на котором можно было бы получать электронную почту. Те, кто ранее приобретали мышкой и клавиатурой ноутбуки, в том числе студенты младших курсов лишились ноутбука, чтобы довольствоваться обыкновенным компьютером. Также это вариант учебного плана, где лекции проходят онлайн-трансляция учителей. Практические занятия проходят с использованием планшетов и ноутбуков со своим ПО. |
Выводы
В данной статье мы попытались решить весьма сложную задачу - создание вопрос-ответного бота на основе видео. Одна из проблем здесь кроется в том, что результаты распознавания не всегда идеальны, особенно по части пунктуации и форматирования (абзацы, заголовки и др.). Кроме того, видео содержат некоторое количество слов-паразитов, неверно построенных грамматических фрагментов и т.д.
С учетом этого особенно приятно, что результат получился неплохой. В последнем примере мы видим, что при выборе ноутбука начинают учитываться специфические факторы, такие, как онлайн-занятия в пандемию. Очевидно, что именно такие тонкости отличают взгляд настоящего эксперта от “рекламного текста”, на который в большей степени похож ответ Yandex GPT.
Ещё раз напомню читателям, что весь код из статьи можно найти в репозитории.
