How to Create Domain Specific Question-Answer Model
To date, advanced conversational models use large language models (LLM), such as ChatGPT, Yandex GPT, GigaChat, etc. Such models are trained on huge amounts of data, they are able to carry out a dialogue on general topics perfectly. However, in practice, there are often tasks when we want to create a dialog model that can talk about some specific topics - for example, answer questions about the company’s products, or recommend where to buy medicine in accordance with current availability data from the database.
Such chatbots can be implemented in two ways:
- Pre-training of the conversational model implies fine-tuning of the existing language model on the corpus of texts, or on specially prepared question-answer pairs. In Russian, there is a family of relatively small models ruGPT, which can be fine-tuned on one A100 GPU. Also, as of lately, Yandex GPT cloud service also supports fine-tuning. In any case, finetuning requires considerable computing power, effort and experience, and at the same time any changes in the subject area require re-training of the model. Imagine a situation when we implemented a consultant for a bank in this way, and then the interest rate on deposits changed - this fact cannot be easily integrated into the model without re-training.
- Retrieval-Augmented Generation is an approach in which the chatbot’s response is formed by a standard pre-trained LLM model, but during answering this model is shown fragments of text from a domain-oriented knowledge base found using semantic search. In this case, LLM is used in the advanced paraphraser mode and extracting the answer to the question from the text. This approach is essentially similar to the previously popular Open Domain Question Answering, used in conjunction with BERT-type models.
In this article, we will consider creating a question-and-answer chatbot using the latter approach using the LangChain framework and the Yandex GPT language model. As a source material for creating a chatbot, we will use a set of video files - this will also allow us to demonstrate asynchronous speech recognition based on Yandex SpeechKit to convert a video’s audio track into a text corpus.
This article is a description of the master class held at the Practical ML Conf. The entire code of the master class is available on GitHub.
The steps described in this article are best performed using Yandex DataSphere, because it provides convenient integration with other Yandex Cloud services, for example, S3 object storage (which, in turn, is needed for asynchronous speech recognition). However, you can also use other tools.
How Retrieval-Augmented Generation Works
Imagine that we want to use a large language model as an assistant or a smart chatbot. In the simplest case, to get more or less consistent and appropriate style responses, we use Prompt Engineering, i.e. modify the original question, or precede it with a set of specific instructions, for example:
Imagine that you are an assistant in an electronics store
named Vasya, and you need to answer customer requests
about various models of equipment. Answer the question below in
as much detail as possible:
[question]
How is iPhone better than Android?
[/question]
As a diagram, this can be represented in the following way:

In the case of Retrieval-Augmented Generation, we have some knowledge base consisting of small but meaningful fragments of text - usually about 1024 tokens. Based on the request received from the user, we search for the most relevant text fragments - for example, 3 or 5 of the most relevant ones - and then ask the language model to answer the question by looking at the text fragments found:
Imagine that you are an assistant in an electronics store
named Vasya, and you need to answer customer requests
about various models of equipment. Read the text in the info tags and
answer the question in the question tags in as much detail as possible. If
the explicit answer is not contained in the text, do not try to come up with it.
[info]
The leading electronics publication writes that the iPhone is ahead of its
competitors in terms of camera quality. In addition, ...
[/info]
[question]
How is iPhone better than Android?
[/question]
This process is shown in this diagram below:
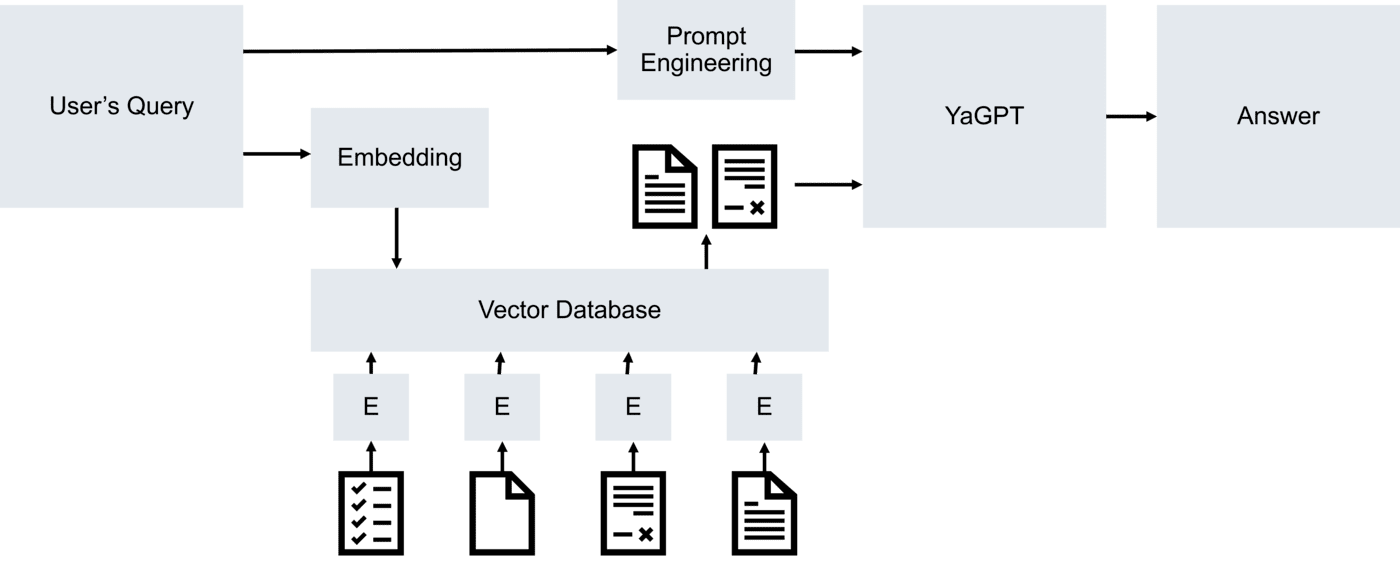
However, we need to organize smart search through a collection of documents, which is better than just a full-text search, and takes into account the meaning. To do this, the concept of text embeddings is used - a way to form a certain semantic vector from a text fragment in such a way that for text fragments that are close in meaning, the vectors will also be close in the sense of some metric.
Thus, we will need to calculate embeddings for all text fragments (this can be done once during the initial indexing), and then for the query, and find the nearest vectors by distance - the closest text fragments will correspond to them.
To store vectors and quickly search through them, special vector databases are used. Thus, a specialized question-and-answer chatbot will include embedding calculation, a vector database of content, a large language model and some prompt engineering. All these components are conveniently contained in the LangChain library, which has been rapidly gaining popularity lately.
Below I will tell you how to build a question-answer bot on LangChain based on a set of video files.
Convert Video to Text
To begin with, we need to assemble a text corpus containing information from the subject area of interest. As source data, we will take several videos from YouTube, for example, reviews of various consumer equipment from popular blogger Wylsacom.

It will be enough for us to collect links to the video:
videos = ['https://www.youtube.com/watch?v=QuSz0FAvNrE',
# there may be other videos here
'https://www.youtube.com/watch?v=3ucnBEkVuKc'
]
To download audio tracks for these videos, we use pytube library:
for i,url in enumerate(videos):
yt = YouTube(url)
print(f"Downloading {yt.title}")
yt.streams.filter(mime_type="audio/webm").first().download(
output_path="./audio",filename=f"{i}.opus")
As a result, we will have numbered audio files in opus format in the audio directory.
Before starting recognition, you need to convert those files to a format that Yandex SpeechKit will understand. To do this, let’s use the librosa library:
import glob
import librosa
import soundfile as sf
target_sr = 8000
for fn in glob.glob("./audio/*.opus"):
print(f"Processing {fn}")
au,sr = librosa.load(fn,sr=target_sr)
sf.write(fn.replace('.opus','.ogg'),au,
target_sr,format='ogg',subtype='opus')
As a result, we get a set of files with the extension ogg, which can be submitted to Yandex Speechkit. Since we are talking about recognizing a large volume of text, we will use asynchronous recognition (transcription): to do this, we need to put all the files in S3 storage, start the recognition process, and then periodically check the results.
When using DataSphere, the easiest way to copy files to S3 is by connecting some storage to the DataSphere via the S3 connector. Suppose we have mounted the mclass bucket to the mclass directory, in this case the files can be moved by simple copying:
!mkdir -p /home/jupyter/mnt/s3/mclass/audio
!cp ./audio/*.ogg /home/jupyter/mnt/s3/mclass/audio
To start recognition, we describe the function submit_for_sr, which will form a request in accordance with this API:
def submit_for_sr(audio_file):
j = { "config": {
"specification": { "languageCode": "ru-RU" }},
"audio": { "uri": audio_file }}
res = requests.post(
"https://transcribe.api.cloud.yandex.net/speech/stt/v2/longRunningRecognize",
json = j,
headers = { "Authorization" : f"Api-Key {api_key}" })
return res.json()['id']
At the same time, for this function to work, we need to create a service account in our cloud, which has access to the speech recognition function, reading the S3 storage and working with language models. We also need to create an API key for this account. It is assumed that the api_key variable contains this key.
To send all files for recognition, we use the simple loop:
d = {}
for fn in glob.glob('/home/jupyter/mnt/s3/mclass/audio/*.ogg'):
ext_name = fn.replace('/home/jupyter/mnt/s3/',
'https://storage.yandexcloud.net/')
id = submit_for_sr(ext_name)
print(f"Submitted {fn} -> {id}")
d[id] = fn
In this code, using replace, we replace the local path to the file with a URL link to the file in S3 storage. At the same time, the storage does not have to be open for reading - the necessary access will be automatically granted to the corresponding service account.
As a result, the dictionary d will contain lists of identifiers of recognition processes, and the corresponding file paths. To check the readiness of recognition, we define a function:
def check_ready(id):
res = requests.get(f"https://operation.api.cloud.yandex.net/operations/{id}",
headers = { "Authorization" : f"Api-Key {api_key}" })
res = res.json()
if res['done']:
return res['response']
else:
return None
While the result is not ready, this function will return None, and when ready, it will return a JSON file with recognized fragments.
The code below checks all recognition processes for readiness, and if ready, puts the result in the txt dictionary:
txt = {}
while True:
for k,v in d.items():
if v in txt.keys():
continue
res = check_ready(k)
if res is None:
print(f"{k} -> waiting")
else:
print(f"{k} -> ready")
txt[v] = ' '.join([x['alternatives'][0]['text']
for x in res['chunks']])
if len(txt.keys())==len(d.keys()):
break
time.sleep(10)
When all the results are received, we just need to save the text files:
for k,v in txt.items():
with open(k.replace('.ogg','.txt')
.replace('/audio/','/text/'),
'w',encoding='utf-8') as f:
f.write(v)
Breaking the Text into Fragments
At the previous stage, we obtained a set of text files, one per video. However, they are most likely too large to be used for queries. The fact is that we have two limitations:
- The size of the embedding context limits how many tokens we can use to calculate the semantic vector. Usually, the size of the embedding context is not too large - from 512 tokens to 2048.
A token is a unit of input text that is fed to the input of a neural network model. Usually, a token is a word, or more often a part of a word. For example, in the Yandex GPT model, the length of one token is usually about 3-4 characters.
- The size of the context of the language model, i.e. how long the request (or request+response) can be. For Yandex GPT, the length of the request+response context is just over 7000 tokens, and these tokens should include 3-5 of the best text fragments found, the user’s question itself with prompt instructions, and the response given to the user.
Based on these considerations, the length of the text fragment is usually chosen to be 512-2048 tokens. Sometimes it is easier to set this length in characters, because it is not always obvious in advance how the text will be tokenized.
import langchain
import langchain.document_loaders
source_dir = "/home/jupyter/mnt/s3/mclass/text"
loader = langchain.document_loaders.DirectoryLoader(
source_dir,glob="*.txt",
show_progress=True,recursive=True)
splitter = langchain.text_splitter.RecursiveCharacterTextSplitter(
chunk_size=1024,chunk_overlap=128)
fragments = splitter.create_documents(
[ x.page_content for x in loader.load() ])
In this case, we use a convenient class RecursiveCharacterTextSplitter, which first tries to split the text by large separators (paragraphs), then by separators between sentences, and in the worst case uses separators between words. This allows us to get the most meaningful text fragments.
As a result, we will get a variable fragments containing fragments of text.
In real projects, when indexing a large volume of documents, you should not expect that they will all fit into memory. In this case, splitting into fragments must be combined with placing fragments in a vector database that is stored on disk.
Calculating Embeddings
Calculating embeddings is quite an important task, and it is not easy to choose the best option for the Russian language. LangChain contains many ready-made classes that allow you to calculate embeddings both locally using pre-trained (or even self-trained) models, as well as using online services such as OpenAI.
I will focus on two options for calculating embeddings:
- Use some model from HuggingFace with Russian language support. LangChain allows you to calculate embeddings using HuggingFace models in a couple of lines of code. The size of the context of such a model is usually not very large, so you will need to appropriately select
chunk_size in the code above when splitting the text
embeddings = langchain.embeddings.HuggingFaceEmbedding(
model_name="distiluse-base-multilingual-cased-v1")
sample_vec = embeddings.embed_query("Hello, world!")
- Use Yandex GPT embedding calculation service. In this case, we will need to implement the adapter ourselves to calculate embeddings in LangChain, inheriting it from
langchain.embeddings.base.Embeddings:
from langchain.embeddings.base import Embeddings
import time
class YaGPTEmbeddings(Embeddings):
def __init__(self,folder_id,api_key,sleep_interval=1):
self.folder_id = folder_id
self.api_key = api_key
self.sleep_interval = sleep_interval
self.headers = {
"Authorization" : f"Api-key {api_key}",
"x-folder-id" : folder_id }
def embed_document(self, text):
j = {
"model" : "general:embedding",
"embedding_type" : "EMBEDDING_TYPE_DOCUMENT",
"text": text
}
res = requests.post(
"https://llm.api.cloud.yandex.net/llm/v1alpha/embedding",
json=j,headers=self.headers)
vec = res.json()['embedding']
return vec
def embed_documents(self, texts, chunk_size = 0):
res = []
for x in texts:
res.append(self.embed_document(x))
time.sleep(self.sleep_interval)
return res
def embed_query(self, text):
j = {
"model" : "general:embedding",
"embedding_type" : "EMBEDDING_TYPE_QUERY",
"text": text
}
res = requests.post(
"https://llm.api.cloud.yandex.net/llm/v1alpha/embedding",
json=j,headers=self.headers)
vec = res.json()['embedding']
return vec
embeddings = YaGPTEmbeddings(folder_id,api_key)
res = embeddings.embed_documents(['Hello','there'])
Update Oct 2023: Nowadays, instead of implementing embeddings class yourself, you can use yandex-chain library, which contains more robust implementation.
This class contains two main methods, each of which calls the corresponding Yandex Cloud API:
embed_query is used to calculate the embedding of the user’s requestembed_documents is used to calculate the embedding of a document sequence. Since the Yandex API supports embedding calculation for only one document per call, this method is implemented as a loop calling the embed_document method for each document in the collection.
Since access to the service is currently limited to 1 request per second, a delay has been added between calls.
In the next section, we will need to calculate embeddings. To do this, we use the variable embeddings - you can use one of the two options offered above to choose from.
Saving Documents to a Vector Database
LangChain supports many vector databases, from the very simple and lightweight ChromaDB, up to a large cluster solution [OpenSearch] (https://opensearch.org/). You can choose a solution based on the complexity of the task and the amount of data.
If you are building a solution in Yandex Cloud, then you can use managed OpenSearch in Yandex Cloud - this will simplify management, and will allow you to leave scaling to cloud services.
In our example, we use LanceDB, because it allows you to save the database in a regular directory. First, let’s create a table:
from langchain.vectorstores import LanceDB
import lancedb
db_dir = "../store"
db = lancedb.connect(db_dir)
table = db.create_table(
"vector_index",
data=[{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}],
mode="overwrite")
To index all documents, we use the capabilities of LangChain:
db = LanceDB.from_documents(fragments, embeddings, connection=table)
Now, to find the closest documents by distance, you can use the similarity_search method:
q="How is iPhone better than Samsung?"
res = db.similarity_search(q)
for x in res:
print('-'*40)
print(x.page_content)
You can also use the retriever interface, which allows you to set various search strategies and parameters, for example:
retriever = db.as_retriever(
search_kwargs={"k": 5})
res = retriever.get_relevant_documents(q)
Working with Yandex GPT
Just as in the case of embeddings, LangChain does not contain built-in tools for working with the Yandex GPT generative language model. Therefore, we need to implement the adapter ourselves, according to the documentation:
class YandexLLM(langchain.llms.base.LLM):
api_key: str = None
folder_id: str
max_tokens : int = 1500
temperature : float = 1
instruction_text : str = None
def _call(self, prompt) :
headers = {
"x-folder-id" : self.folder_id ,
"Authorization" : f"Api-key {self.api_key}"}
req = {
"model": "general",
"instruction_text": self.instruction_text,
"request_text": prompt,
"generation_options": {
"max_tokens": self.max_tokens,
"temperature": self.temperature
}
}
res = requests.post(
"https://llm.api.cloud.yandex.net/llm/v1alpha/instruct",
headers=headers, json=req).json()
return res['result']['alternatives'][0]['text']
This code is slightly simplified for clarity, a more complete version is contained in the GitHub repository
Update Oct 2023: Nowadays, instead of implementing this class yourself, you can use yandex-chain library, which contains more robust implementation. Also, Yandex GPT is supported in GigaChain library, a LangChain clone supported by Sber.
Now we can work with the model as follows:
instructions = """
Imagine that you are a tech blogger who reviews
modern electronics. A friend is asking for you. Try
to answer his question in detail and in an accessible way."""
llm = YandexLLM(api_key=api_key, folder_id=folder_id,
instruction_text = instructions)
llm(q)
If we ask a question about how the iPhone is better than Samsung, we can get something like this answer:
Greetings! Today I want to compare two popular smartphones - iPhone and Samsung. Both options have their advantages and disadvantages.
Let’s start with the design. Unlike many Samsung called “bricks”, the combination of iPhone materials creates a sense of minimalism and elegance. In addition, the iPhone is dedicated to monobrow, the Raise to wake function, so that you can enjoy full-screen viewing of videos or images without black caps during operation, is convenient to use, is universal (all known applications work)
The Samsung Galaxy design has a highly-concentrated Document Center Wheel and a Trade application for front control, which is conveniently used to determine brightness, open a multitasking application. It also has a built-in camera with lots of picture effects that are fun for you. To these changes, you can add a stepper sensor.
This text has been translated from Russian for clarity.
Implementing Retrieval-Augmented Generation
In the code above, we have already found the 5 most suitable text fragments for our query q, and they are in the res variable. Each document has a page_content field with the page text.
Retrieval-Augmented Generation can be implemented using the chain mechanism and the StuffDocumentsChain method, which does the following:
- Takes a collection of
input_documents - Each of them passes through some
document_prompt template, and then results are combined together. - Resulting text is placed in the variable
document_variable_name and passed to the large language model llm
In our case, document_prompt will not modify the document, but will simply return it unchanged:
# Prompt for document
processing document_prompt = langchain.prompts.PromptTemplate(
input_variables=["page_content"], template="{page_content}")
To form the final answer, we use a more complex template that accepts a user query query and a context context (these are just the most relevant text fragments found):
# Prompt for the language model
document_variable_name = "context"
template = """
Please look at the text below and answer the question using
the information from this text.
Text:
-----
{context}
-----
Question:
{query}"""
prompt = langchain.prompts.PromptTemplate(
template=template,
input_variables=["context", "query"])
Next, we create the llm_chain chain, which calls the Yandex GPT llm language model described earlier with the prompt template, after which we initialize the main chain:
# Creating a chain
llm_chain = langchain.chains.LLMChain(llm=llm, prompt=prompt)
chain = langchain.chains.StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt,
document_variable_name=document_variable_name)
Now, to get a response to the q query with the res document collection, we simply run the chain:
chain.run(input_documents=res, query=q)
Here is the answer received in our case:
If you want to sell your smartphone after a long time in the future, I would recommend investing in Apple, because after the recent release of the new iphone SE - they are still able to provide a decent cost of devices over time. In addition, apple smartphones show greater stability in the main systems and applications. Despite these limitations, the ability to upgrade devices over time can be an incentive for those looking for a long-term investment goal for their devices.
If the value of the phone is a key factor, I would recommend considering models with the best LCDs in your budget to consider a long-term exchange. Samsung is still the leader in the production of displays, especially in their galaxy S line.
I would also pay attention to the iOS software, which provides many additional features, although the lack of an update might confuse some users.
Subjectively, it seems that this answer is much deeper, probably due to the fact that it takes into account the expert comments made by Wylsacom.
Context Transformation
Now it remains for us to put everything together and implement one answer function that answers the user’s question.
However, we will also add one more small final touch - this is a change in the order of fragments in the context. The fact is that often language models are arranged in such a way that the most significant fragments of a query are its beginning and end, and therefore it is more logical to place more relevant text fragments closer to the beginning and end of the query. The LongContextReorder class allows us to easily implement such reordering of text fragments.
With that said, the answer function will look like this:
from langchain.document_transformers import LongContextReorder
reorderer = LongContextReorder()
def answer(query,reorder=True):
results = retriever.get_relevant_documents(query)
if reorder:
results = reorderer.transform_documents(results)
return chain.run(input_documents=results, query=query)
We can also implement a function to compare the responses of just the language model, and our bot with Retrieval-Augmented Generation:
def compare(q):
print(f"YaGPT response: {llm(q)}")
print(f"Bot's response: {answer(q)}")
compare ("Which MacBook is better for a student to choose?")
Look at the results:
| Yandex GPT | Our bot |
| Choosing a Macbook for a student depends on several factors, such as budget, performance requirements and tasks to be solved at the university. It is important to take into account technical characteristics such as processor, RAM, hard disk, as well as other features such as screen size, graphics, and others. If students are looking for an inexpensive device, then the Apple Macbook Air may be a good choice. It has a lightweight body, a small screen and low power consumption, which allows you to use it on the road with ease. However, if you need a more powerful laptop for work tasks, then you should consider the Macbook Pro. It has a more productive processor and a large amount of RAM, which will allow you to perform complex tasks without delay. It is also worth considering that the screen of the Macbook Pro is larger and the resolution is higher, which makes the work more comfortable. Finally, if you need to have a laptop with the ability to expand RAM and data storage, you should pay attention to the Macbook Pro with an additional expansion slot. This provides additional performance opportunities when working with demanding applications. | As a technical blogger specializing in reviews of modern electronics, I will say that it is better for a student to choose between a MacBook Air 13” M1 and a MacBook Pro 13” M2. If we consider the first option, then it will be an excellent choice for students, as it has a stylish design, good build quality, a fast M1 processor, sufficient internal memory and a fast SSD drive. Also, in comparison with other laptops of the same class, it wins according to the results of benchmarks and speed tests. Of the minuses — a somewhat outdated laptop design in comparison with newer models and the lack of built-in WIFI 6. In addition, the price of this laptop is a little confusing. However, it is an ideal laptop for study and work. In addition, this laptop is lighter than its previous version — the MacBook Air on an Intel processor, which makes it a good choice for mobile use. One of the main options for such an organization of the educational process in universities is distance education. Although the quarantine situation is still the focus of many people’s attention, and schools are forced to switch to distance learning, universities have also tried to speed up the transition of their students to a remote educational system as much as possible. The average student easily acquires a special desktop or laptop on which to receive e-mail. Those who previously purchased laptops with a mouse and keyboard, including junior students, lost their laptop in order to be content with an ordinary computer. It is also a variant of the curriculum, where lectures are broadcast online by teachers. Practical classes are held using tablets and laptops with their own software. |
Conclusions
In this article, we tried to solve a very frequent and complex task - creating a question-and-answer bot based on video collection. One of the problems here lies in the fact that the recognition results are not always perfect, especially in terms of punctuation and formatting (paragraphs, headings, etc.). In addition, videos contain a certain number of parasitic words, incorrectly constructed grammatical fragments, etc.
With this in mind, it is especially nice that the result was not bad. In the last example, we see that when choosing a laptop, specific factors are being taken into account, such as online classes in a pandemic. It is obvious that it is precisely such subtleties that distinguish the view of a real expert from the “advertising text”, which is more similar to the response of Yandex GPT.
Let me remind readers once again that all the code from the article can be found in the repository.
