 |  |
|---|
| Berlin City Landscape, Oil Painting - Stable Diffusion | Pastel Drawing of a Man and a Woman Standing in front of the Sea at Sunset, Kissing - Stable Diffusion |
Neurogenerative Models
In the last months we have seen very fast progress in the area of neural models that can generate images based on text prompt - so-called text-to-image. The first serious model, which appeared in January 2021, was DALL-E from OpenAI. DALL-E 2 followed in April, 2022, and the model from Google - Imagen - came at about the same time. Both models are not open for general use, model weights are not available, and their use is only possible as part of services undergoing closed beta testing.
However, neurogenerative models were mostly made popular by Midjourney, which is trending recently among art enthusiasts. The model is targeted at art creators, which is the result of using special dataset for training. However, Midjourney is also not free to use - you only get about 20 free image generations to experiment with.
 |  |
|---|
| dark abandoned city, with yellow street lights and hopeless people on the street, trending on artstation | by Midjourney |
There are, however, open neurogenerative models being actively developed, whose weights/code is available in open source. Up until recently, the most popular approach was VQGAN+CLIP, described in this paper, and which is based on CLIP model made available by OpenAI. CLIP is able to match how well text prompt corresponds to a given picture, so VQGAN+CLIP iteratively tunes the VQGAN generator to produce images that correspond to the prompt better and better.
 A pilot in front of his plane - VQGAN+CLIP
A pilot in front of his plane - VQGAN+CLIP
There is also a Russian variant of DALL-E, called ruDALL-E, which has been trained by Sber/SberDevices and AIRI. Those models and weights are freely distributed, and they use Russian as prompt language.
 Cats, generated by ruDALL-E
Cats, generated by ruDALL-E
An important milestone for neural art community happened on August 21, 2022 - code and weights of the state-of-the-art neural generative model called Stable Diffusion were openly released by Stability.AI
Stable Diffusion
In this post, I will not discuss in detail how Stable Diffusion works. In short - it combines the best ideas from Imagen (using frozen weights in text interpretation model during training) and the previous generation of generative models, called Latent Diffusion. The main idea is to use autoencoder to transform original 512x512 pictures into lower dimensional space - so-called latent representation, and then synthesize this representation instead of the full picture using diffusion process. Compared to models that operate on pixel representation, latent diffusion takes less time and computational resources, and gives better results. Stable Diffusion was trained on open LAION dataset.
I had access to early stages of Stable Diffusion training, which gave me some time to prepare this short overview of its capabilities.
 |  —— —— | —— |
| Oil Portrait of Young Male Teacher of Computer Science - VQGAN | Watercolor Painting of Young Female Teacher of Computer Science - Stable Diffusion | |
As this example shows, Stable Diffusion gives significantly better result compared to VQGAN+CLIP. That’s why I believe that public release of Stable Diffusion model is an important step for art/design ecosystem, because it gives artists very powerful new capabilities of neural image generation.
As the creators of Stable Diffusion note, finally we have the model at our disposal that knows a lot about images in general. For example, the model knows how most of the celebrities look like (except for my favorite Franka Potente):
 |  |  | 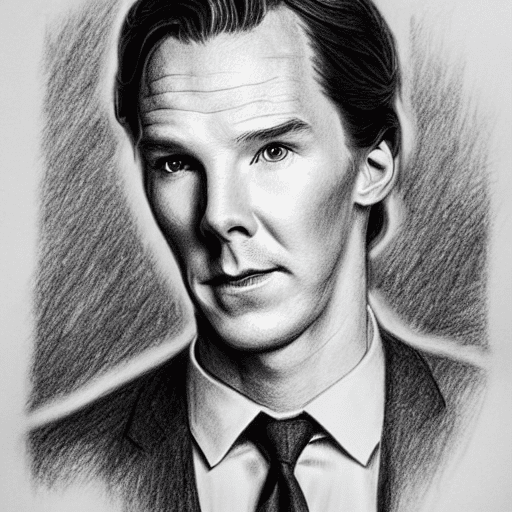 |
| Oil Portrait of Harrison Ford | Watercolor Portrait of Scarlett Johansson | Pastel Drawing of Jared Leto | Pencil Drawing of Benedict Cumberbatch |
This example also shows that the model can create images using different techniques: oil, pastel, watercolor or pencil sketch. But that’s not all - it also can mimic the style of specific artists:
 |  |  |  |
|---|
| Edvard Munch | Pablo Picasso | Salvador Dali | Van Gogh |
In the example above, we used prompts large city landscape by + artist name.
Moreover, the network knows the famous attractions of world capital cities:
 |  |  |  |
|---|
| Seattle, Pencil Sketch by Stable Diffusion | Paris, Oil by Stable Diffusion | Moscow, Watercolor by Stable Diffusion | London, Oil Painting by Stable Diffusion |
The examples above demonstrate the ability of the network to memorize images and combine them with different styles/techniques. We can also try to see how the network can imagine abstract concepts, such as love, loneliness or despair:
 |  |  |
|---|
| An abstract concept of love, cubism | An abstract concept of loneliness | Separation, in the style of impressionism |
How to try it?
The simplest way to try Stable Diffusion is to use Dream Studio, a tool recently released by Stability.AI. At the moment it only includes generation via text prompt, but soon they promise to add additional features, such as inpainting or image-to-image generation. It gives you a limited number of image generations to play with.
Similar tool for neural image generation is Night Cafe. In addition to generation, you can also become part of the community, share your results and take part in discussions.
For those of you who can handle Python and Pytorch - feel free to use Colab Notebook.
Where/How Neural Generation Can be Used
Once you get his very powerful neural generation tool and have a chance to play with it, you soon start asking the question - so what? How can you use this tool?
Of course, you can now generate a lot of beautiful images of paintings, print them on canvas and start selling on the local flea market. Or you can claim authorship on those pieces (or at least joint authorship with AI), and start arranging your own exhibitions, or taking part in third-party ones. But is it that simple?
Let’s put aside the question on whether you can call AI creations “art”, and how much you can earn by selling “cheap” pictures. Let’s think about other productive uses of neural generation:
- Inspiration by Randomness. Sometimes, in the search for a new idea or composition, artists randomly splash paint on canvas, looking for inspiration, or they use wet watercolor paint to try and accommodate that random diffusion of colors into overall picture. This element of randomness is exactly what a neural network does - it randomly puts together patterns from the images it has seen before in the training dataset. In many cases, neural network can give us unexpected result - like in the example below, when we asked it to generate a man with triangular mouth, but got an interesting image with red things around the mouth. This unexpected image can give a new direction of thought to the artist.
 |  |
|---|
| Scary photo of a man with mouth wide open in the form of big circle | Scary photo of a man with his mouth in the form of a equilateral triangle |
- Drawing Artefacts. In some cases, the main value of a piece of art lies in the idea and the message, and not so much in the actual implementation. Imagery as such plays a secondary role, and we can employ AI to generate those images. As an example, we can use AI to generate images for a marketing banner, or many images of people of different nationalities for some international event.
 |  |
- One of the ways to get inspired is by watching neural generation stream, produced by different people. This is a good way to see a lot of very different ideas in a short time, to broaden our thought horizons, and to help us generate new thoughts, which we then express in traditional ways. I will talk more about this later.
- Use neural generation as a starting point, or as one of the steps towards the final artefact, in addition to traditional digital tools and techniques. This gives us better control on how to express the original idea, and make us truly co-authors of the artefact, allowing to merge the ideas of AI and our own.
- A variation of previous point is to use neural generations sequentially, using techniques such as inpainting (an ability to re-generate or fill an area within the image using neural generation), image-to-image (when we use text prompt together with the initial sketch, showing overall composition, and ask the network to produce detailed image), or searching through latent space to find variations of the image originally created.
- Neural generation for education. Since generative networks “know” styles of well-known artists and different artistic techniques, we can use this in art education by generating sample images on the fly. For example, we can take an everyday object (such as spoon), and ask the network to draw it using styles of different artists. This make education more interactive, and is likely to have more emotional effect on learners, because they become a part of creation process themselves.
I am sure you can think about many other usages of text-to-image neural generation! Feel free to suggest them in the comments!
By the way, an interesting issue that we still need to figure out is copyright on the artefacts produced by those processes. Companies owning closed networks (such as DALL-E/OpenAI) usually claim the ownership of the results generated by the network, while Stable Diffusion employs much more open The CreativeML OpenRAIL M License, which gives artist the ownership (and responsibility) for the created content, at the same time explicitly prohibiting certain unethical usage scenarios.
Art of Prompt Engineering
Text-to-image generation may seem deceivably simple, but in fact, to get the desired result, it is often not enough to write a short prompts such as “a girl”. The example below show how we can make the prompt more elaborative to achieve the result we want:
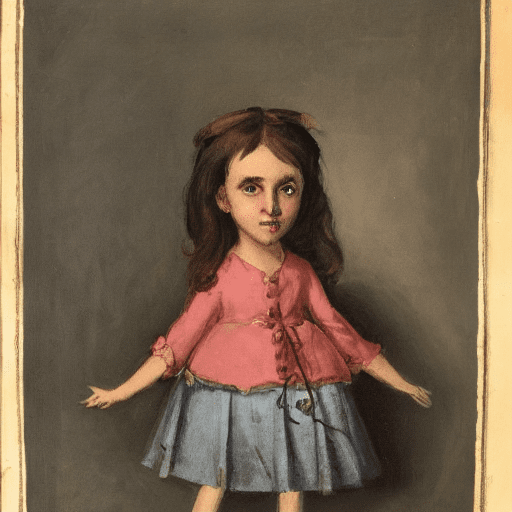 |  |  |
|---|
| A Girl | Portrait of a Beautiful Girl | A Beautiful European Girl with Long Blond Hair and Blue Eyes, Unreal Engine, Trending on Artstation |
The network has seen a lot of images and knows a lot, yet sometimes it is very difficult to achieve some specific results, because the network’s imagination is limited. In other words - it has never seen such combinations in the training dataset, and it is having difficulties combining several high-level concepts together. A good example is the image of a man with triangular mouth that we have seen above.
To achieve the result which is close to the imaginary picture you have in your head, you are likely to need several text prompts, using some of the special tricks to fine-tune the image. Here are some of those tricks:
- Explicitly mentioning the technique: watercolor portrait of Bill Gates, or Bill Gates, oil on canvas
- Providing the name of specific artist in the prompt: portrait of Bill Gates, by Pablo Picasso - Stable Diffusion Artist Guide
- Providing dates/time period: Bill Gates watching schematic plan of IBM PC Personal Computer, old photo, 1960s
- Using some modifiers: sepia, matte, high detail, etc. Guide on Stable Diffusion Modifiers
- Using some extra modifiers that are likely to be present in the training dataset, such as Unreal Engine, trending on artstation, 8k, etc.
In addition to the prompt itself, you can control some other generation parameters:
- Image Size. Stable Diffusion was trained on 512x512 images, but you can specify different image size during generation, the main constraint being the video memory of your GPU. However, keep in mind that the network tries to fill all area of the image with some meaningful details. For example, if you ask for a portrait in a wide horizontal image, the result will likely contain several portraits of people. A way to overcome this is to explicitly as the network to draw something in the empty space.
- Number of steps of diffusion. Small number of steps leads to less detailed image, and there are cases then it looks good. However, as a general rule, the more steps - the better. Examples
- Guidance Scale (or cfg scale) parameter controls the weight of text prompt, i.e. it specifies how exactly the resulting image should correspond to our prompt. Smaller number gives network more flexibility to draw what it wants, which often leads to more consistent image. Higher number sometimes leads to confusing results, but generally better suite the prompt.
Can AI be Creative?
About two years ago I was thinking about the same question in my blog post on AI and Art. Since then, the process of creating AI art was dramatically simplified. At the time of GANs, an artist had to collect the dataset of images selected according to some criteria, train GAN model (which does not only take time, but is in general very tricky process), and then cherry-pick a few good artefacts our of 100+ generated images. Nowadays, almost any image generated by Stable Diffusion or Midjourney looks relatively good.
It is indeed questionable whether we shall call an art something created in a matter of few minutes from an idea that has just occurred to us. I like to adopt a principle whereas an art is something people are ready to pay for - however, according to this principle we are highly unlikely to see considerable demand for thousands and millions of Midjourney / Stable Diffusion generated images that are now flooding the internet.
A proper AI art is always created by a joint effort by a human being and a neural network. As AI becomes more capable, a human artist needs to think about the added value he/she can bring. Without the sufficient value we add - we cannot feel proud or truly claim ownership of the work, nor will we have the feeling of accomplishment.
Another side of thinking about the value we bring is to think about the value AI can bring to our artistic process. But we need to think about the balance.
When using text-to-image models, even when we don’t apply any post-processing to the image, and important role of a human artist is the following:
- To come up with the original idea. An piece of art is created to make some statement to the world and to have an emotional effect on the viewers that will amplify this statement. Only a human being that has desire to create and self-express can know what he/she wants to say to the world. A neural network does not have a desire for self-expression.
 |  |  |  |
| People and Robots - Dmitry Soshnikov via Stable Diffusion |
- Prompt Engineering that we have already talked about.
- Cherry-pick the result according to some criteria of beauty or emotional effect, which only a human being has. Even though there are attempts to collect datasets of images that “resonate” and are emotionally strong, right now it is not feasible to formalize the concept of beauty, or build a classifier that will determine good art from the bad.
- Think about positioning the work and how to make it known to the world, or how to “sell” it (in the broad sense of this word). A generated image that no-one except you will see present very little value for the humankind. Unless people will find it later on after your death and it will make you famous - but I would not count too much on this.
As I have already emphasized, random text-to-image generation is not too interesting, and in many cases we would see artists using neural generation to materialize their idea, using tools like inpainting, image-to-image, generating video (Voyage through Time is a great example), or exploring latent space and seeing corresponding image transformations.
At some point of time in the past, photography replaced classical portraits and landscape drawings, forcing artists to look for more creative ways to visualize our reality. Similarly, neural art generation would lead to more interesting ideas and techniques, and will raise a bar of creativity for artists.
New Ways to Experience Neural Art
We often come to museums and galleries to experience traditional art. In a way, museums and galleries show curated content, which has been filtered by the community. Digital nature of AI-generated art allows for different form of curation. Also, because generating AI image is much “cheaper” than producing traditional painting, we are facing much larger volume of imagery.
Initially, generative models such as Stable Diffusion and Midjourney were opened to beta-testers through Discord communities, where you could use a bot to do generation. Stable Diffusion community had more than 40 channels, each of them being an almost constant flow of imagery generated from someone’s text prompt. Network creators used those feeds to test the model on large volumes of very diverse text prompts.
Neurogenerative Streams
Being in this community as one of the members, I noticed that watching this constant stream of diverse images is very inspiring! Unlike a museum, where we see relatively small number of works, each of them having a great artist and a story behind it, in neurogenerative stream we see a huge flow of uncurated images that are cheap to create. However, this does not make those artefacts uninsteresting - many of them contain original ideas, or at least hints, which make our brain burst out with our own ideas and emotions. We just need to adjust our “art consumption habits” to handle this constant stream.
You can compare visiting a museum to a restaurant, where you enjoy carefully chosen dishes and wine selection. Consuming neurogenerative stream would then be like a all-you-can-eat buffet, where you have a mix of international dishes, with 20 types of soda drinks.
Neurogenerative channels in Stable Diffusion discord were chaotic, but we can as well imagine separating those channels by topic, so that all images in one stream have some thematic constraints. For example, we can have one stream showing cats and kittens, and another one for the landscapes of distant planets.
Integration of Neural Generation in Art Objects
One of the ways to use neural generation is to build it into a larger art object, where the final result will be generated from a text prompt that was somehow automatically constructed. As an example we can imagine a system that will take a profile of an individual in social networks, somehow extract his verbal portrait from his/her posts, and then use Stable Diffusion to produce a social network portrait.
Neurogenerative Parties
It’s not a secret that we get more emotionally involved if we have a chance to participate in the process of art creation through some sort of interactive process. Also, let’s take into account that the important role of art is to encourage us to think, and even better - to have a dialog and arrive to some conclusions.

A great way to have this interactivity and dialog is to organize a neurogenerative party - a format which we have recently tried out with a couple of friends, and now are looking to expand to a larger scale. An idea is to bring together a group of people (preferably offline, with some wine and appetizers, but online is also an option), and do neural generation together.
Here are also some rules to make it more structured:
- Fix a topic for the party, eg. loneliness, love or meaning of life. This will limit our exploration, but also make it more meaningful, focused around an important idea that we want to explore.
- We can start the generation with a very simple prompt, and then make it more detailed, depending on what exactly we want to see in the picture. For example, we can start with the word “loneliness”, and then arrive at something like “two old people looking away from each other”. We can take additional meanings and ideas both from the images generated by the network, and from the dialog with the audience and group discussions.
- We can also ask the audience for the word associations they have with the concept being explored, and which styles and artists are associated with it. We can then immediately experiment and get visual confirmations.
- All the steps of neural generation should be documented/saved, and as a result of the party we can publish the best results - in the blog post, or an article, or even think about taking part in an exhibition.

Why I believe this format is great:
- Neural generation acts as a unifying reason to talk about an important topic. Even is we do not create any great artefacts (which is unlikely) - we will enjoy talking with each other. This talk would be structured, and it is also a great way to get to know each other.
- During the party we will all see a number of freshly created art pieces, which can be compared to collectively visiting a museum.
- Images would be created right there, from the prompts that we come up with - which makes every participant a co-creator, and gives his the pleasure of creativity and dopamine from the quick result.
To have a successful party, the following roles are important:
- Prompt Master - a person who has some experience with neural generation, and who can tweak text prompts. In most of the cases, he is also the person who would take care about the technical aspects - how to run Jupyter Notebook or neural generation tool, how to save images, etc.
- Art Expert, who knows different art styles and techniques, and who can also direct the creative process and estimate how valuable the result is.
- All other participants do not need special skills, and can take more active or passive role as they like. However, encouraging people to take active part is a good idea - you might also need a facilitator for this.
In case you want to take part in one of those events - subscribe to my telegram channel (in Russian)!

Takeaway
We are living in a very interesting time, when a neural network becomes creative (does it, really?), and can automate more and more work of a visual artist or story writer. I truly hope that it will lead to new forms and styles of art being created by us, humans, and that it will expand and enrich our perception of the world. For this to happen, it is important for us not only to watch this scene carefully, but to actively get involved and experiment!


