Jump directly to the challenge
This post is a part of AI April initiative, where each day of April my colleagues publish new original article related to AI, Machine Learning and Microsoft. Have a look at the Calendar to find other interesting articles that have already been published, and keep checking that page during the month.
If you were reading some of my earlier blog posts, you know that I like using different AI techniques to produce some Science Art, such as Cognitive Portraits or GAN Paintings like that:
A lot of other artists are also using Artificial Intelligence to create their pieces. For example, virtual composer AIVA has been recognized by SACEM French Music Society. In fact, an attempt to use computers to produce music started much earlier with Alan Turing. Lately, on last Microsoft Digital Transformation Summit, our partners at Awara IT combined music and visual arts in the “NeuroKandinsky” performance.

Can AI Create a Piece of Art
To figure this out, we first need to come up with the definition of art. The definition in Wikipedia is the following:
Art is a diverse range of human activities in creating visual, auditory or performing artifacts (artworks), expressing the author’s imaginative, conceptual ideas, or technical skill, intended to be appreciated for their beauty or emotional power
For some reason, it explicitly limits artistic activities to humans. However, if we look at the piece of art by itself, without referring to its history, it would sometimes be hard to tell who was the original creator, human being or not. This, it would probably make sense to adopt another definition or art, which would allow us to distinguish art from garbage without looking at the author:
A piece of art is an artifact that is somehow valued by art connoisseurs, for example, by being payed for at auctions.
Which is to say that if an artistic piece is bought for a high price at an auction – it is definitely art. Remember the case with Edmond de Belamy piece sold for more than $400K at Christie’s?
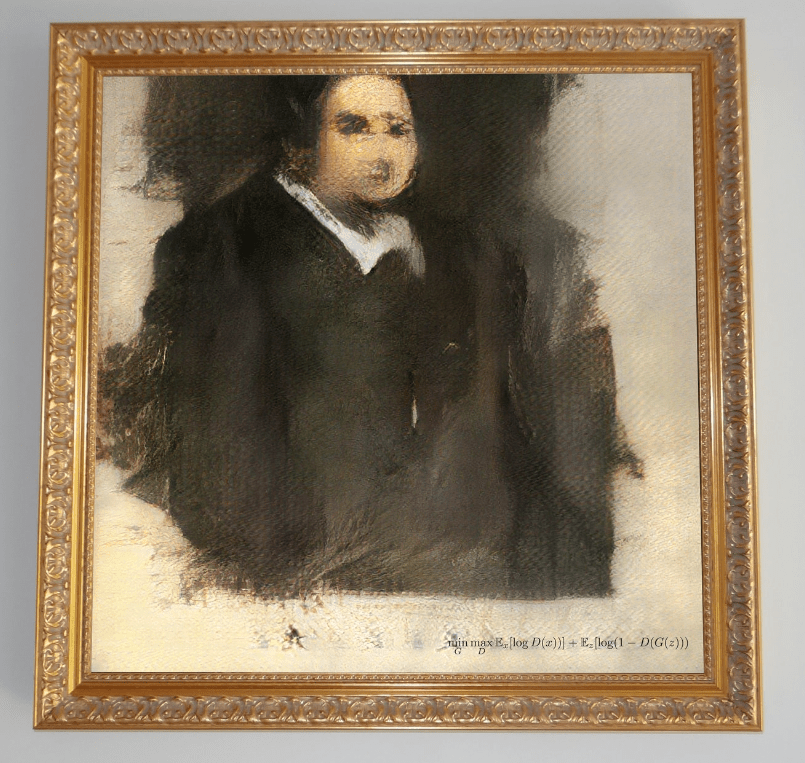
However, this definition does not reflect the inner value or beauty of an artifact, because in the case mentioned above the buyer payed such a high price not for the artwork as such, but rather for the fact of buying the first AI-created art piece. It is the same reason why most of the price for Coca-Cola or Pepsi bottle is not the price of a drink, but of brand. So the actual value lies not in the artwork, but in the story behind it, and this story is created by a human being.
Who Actually Creates Art
So, we have come to realize that it is always a human being who creates a story behind a piece of art, because only human beings have a motivation to be creative. Now let’s talk about the process of creating an artwork.
In the case of Cognitive Portrait we used AI to extract coordinates of facial landmarks from people’s faces, which helps us to align pictures together in a certain way. How the pictures are aligned is defined by an algorithm written by a human being, and this algorithm helps her/him to achieve certain artistic effect and carry a specific message.
For example, this picture is constructed from about 50 photos of my daughter, which are grouped together by age intervals, to reflect the process of her growing up. And the following piece, produced from the same set of photos, represents the circular structure of time, when you are caught up in some whirlpool of places and events:
So, quite clearly, when creating cognitive portraits we used AI as a very powerful tool that helped us with image editing. We could have actually performed the same process in Photoshop manually, aligning all photos, but it would be much more time-consuming and limiting compared to using an algorithm.
The case with Generative Adversarial Networks is more complex to tackle, because it looks like the Neural Network, after having been trained on a dataset of human artworks, has learnt to produce new original art pieces all by itself. In fact, the network learns similar to a human being learning to see or draw: when looking at many images it learns which low-level pixel combinations are used that represent brush strokes, and then how those strokes are typically combined together into larger objects, finally leading to the whole picture composition. In the same way a child learns to see by making sense of light patterns around him, and then painter looks at many earlier artworks to gain some inspiration.
Unlike human being, neural network then randomly combines those pieces of knowledge into a painting, while a human artist would most probably have some goal or idea in mind, which he wants to express using techniques that he has previously seen or tried.
Human beings have a goal, an idea, a motivation that directs his/her work, while artificial intelligence acts randomly.
As an example, look at the two pieces produced by the same network:
 |  |
| - | Countryside, 2020 |
Two images for us look quite different, somehow we know that image on the left is garbage, and the one on the right is not, because it creates some feelings inside us. However, for a computer those two images are more or less the same, and in fact they were scored similarly by GAN discriminator. So the human being is the one who holds the truth, who knows how to tell the good from the bad.
In order to create the artwork like the one above, the human has to:
- Select the dataset of the images to be used for training. Keep in mind that all those pieces were also created by human beings, reflecting our view on what is beautiful, and what is not.
- Perform hyperparameter optimization, selecting the parameters for the network which lead to the best results.
- Select the best works from hundreds of images generated by the network. Last two steps are something which requires human inspection and human understanding of what to consider art.
- Create some story behind the artwork, which at least requires naming it, and then possibly putting it up for sale at an auction, creating artistic value.
Creating artificial art is a joint process, where human artist works together with artificial intelligence tool to produce the artistic impact that he wants.
Actually, the problem of “who is the author of an artwork” has been considered much earlier than AI came about, and it is not specific to AI. For example, Japanese Photographer Tetsuya Kusu used a camera that periodically takes pictures, and collected a gallery of artworks that were taken by the camera itself during his travel through US. This process is in fact very similar to our GAN case: to come up with something beautiful a human being needs to filter out a lot of crap from automatically-generated images. Human being is the one who understands the criteria of beauty, not the camera, and not the artificial neural network.
This process of selecting something beautiful from garbage is similar to random walk search, which is definitely much less effective than gradient descent. It is more effective when an artist starts with some idea in his head, and then implements it on canvas. In the GAN case, the idea and the story come second, after the piece has been generated by random combination of patterns.
A Challenge
At the end of this post, I want to challenge you to express your creativity and to prove that AI is in fact only a tool – but a very useful one, which empowers software developers to be creative in the field of visual arts. I would challenge you to create your own Cognitive Portrait!
To do so:
- Go to Cognitive Portrait Repository: http://github.com/CloudAdvocacy/CognitivePortrait
- Have a look at the sample code there, which is presented in the form of Jupyter Notebooks. The easiest way to do it is to open the code in Azure Notebooks.
- Fork the repo, and create your own portrait! I recommend following some rules:
- If you are going to change the code in the notebook - please copy the notebook to a new file, so that original code is preserved. This would allow people to see both the original code and your new code.
- If you are uploading your own pictures – create a subdirectory under
images/, so that your pictures do not interfere with others. - Place the sample image from your script into
results folder, so that it is easy to see. - The front page
readme.md contains the gallery of different cognitive portrait techniques, please add your name/resulting image there. - Finally, do a pull request, and I will include your code into the original repository!
Some ideas for you to explore:
- Start simple - just create your own cognitive portrait, by uploading your images into
images/your_name, running one of the notebooks which are already there, and then storing the result into results/your_name.jpg. - Once you do that - copy one of the notebooks into a new file and start experimenting! You may try to position eyes along some geometrical curve, or adding some random movement to faces within cognitive portrait, or do some other crazy things related to the coordinates of facial landmarks!
- Face API can also return you a lot of useful information about the face: age, gender, head rotation angle, emotions, etc. You can use that information to filter out some of the faces, for example you may want to leave only faces looking straight into the camera, or group together only happy faces.
- Do not forget to add your creation to the
readme.md and do a pull request!
At the end of the month, I will feature the best creations in my blog and social networks, and we will all celebrate together!



