Я верю в то, что не только красота спасёт мир, но ещё и междисциплинарность. Поскольку моя дочь любит искусство, а я люблю программировать — я часто присматриваюсь к пересечению этих областей, которое можно назвать генеративным искусством (generative art), и которое является частью Science Art. В этой статье я хочу поделиться результатами одного креативного эксперимента по рисованию портрета, из которого родилась техника Cognitive People Blending:
 |  |
| Glass Girl, 2019 | Vickie Rotator, 2019 |
Эти портреты создавались из нескольких фотографий, наложенных друг на друга таким образом, чтобы глаза совпадали — при этом основные черты лица подчеркиваются, фон размывается, и получается любопытный смешанный портрет. Такое безусловно можно сделать в PhotoShop, но это мучительно, и не оставляет места для быстрых экспериментов с разными фотографиями. Ниже я покажу, как такие портреты можно создавать автоматически с помощью когнитивных сервисов Microsoft и небольшого количества креативности. Вы сможете найти весь рассматриваемый мною код в этом репозитории, и сразу начать использовать его с помощью Azure Notebooks. Если вдруг Вы создадите шедевры в этом жанре — пожалуйста, ссылайтесь на Cognitive People Blending.
Основная идея
Для начала, нам понадобится набор портретных фотографий — это могут быть фотографии одного человека, или разных людей, которых мы хотим смешать вместе. Чем больше у Вас будет фотографий, тем интереснее, но меньше 10 фотографий точно брать не стоит.
Для нахождения координат глаз на фотографии мы будем использовать Face API, который умеет извлекать так называемые опорные точки лица. Затем мы применим аффинное преобразование, реализованное в библиотеке OpenCV, чтобы совместить глаза на всех фотографиях. Наконец, мы смешаем все изображения вместе, чтобы получить результат.
Извлекаем опорные точки лица
Для начала научимся определять по фотографии координаты опорных точек лица. Microsoft Face API предоставляет простое REST API для анализа лиц, которое помимо опорных точек может извлечь ещё уйму полезной информации — пол, возраст, углы поворота головы, эмоции, наличие бороды и т.д.
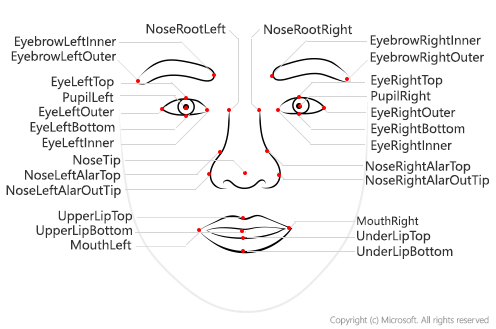
Сравнительно несложно вызвать Face API напрямую по протоколу REST, но ещё лучше — использовать специальный SDK для Python, входящий в состав Azure SDK library. Более детальная информация по вызову Face API из других языков содержится на Microsoft Docs.
Для установки SDK (а заодно и OpenCV, который нам тоже понадобится), введём следующую команду в консоли операционной системы:
pip install azure-cognitiveservices-vision-face opencv-python
Если Вы используете Azure Notebook, то используйте префикс ! и вводите код в обычной ячейке — пример можно посмотреть тут.
Для использования Face API нам необходим ключ и endpoint URL, которые можно получить несколькими способами:
Важно: Если Вы используете пробный ключ, у Вас будет ограниченный доступ к Face API по количеству изображений, которые Вы сможете обработать, и по числу запросов в минуту (не более 20 шт.). Если при этом Вы захотите в этом примере обрабатывать более 20 фотографий — Вам нужно будет вставить задержку между вызовами, чтобы не превысить это ограничение.
Полученные ключ и URL запомним в переменных key и endpoint:
key = '--INSERT YOUR KEY HERE--'
endpoint = 'https://westus2.api.cognitive.microsoft.com'
Основные запросы к Face API делаются через статический модуль cognitive_face, который мы для краткости будем называть cf:
import azure.cognitiveservices.vision.face as cf
from msrest.authentication import CognitiveServicesCredentials
cli = cf.FaceClient(endpoint,CognitiveServicesCredentials(key))
Основные функции для анализа лиц — это face.detect_with_url и face.detect_with_stream. В зависимости от указанных параметров, они могут извлекать много полезной информации — в нашем случае нам нужны лишь опорные точки (facial landmarks):
im_url='https://2016.dotnext-piter.ru/assets/images/people/soshnikov.jpg'
res = cli.face.detect_with_url(im_url,return_face_landmarks=True)
print(res[0])
В результате мы получим массив res, каждый элемент которого соответствует найденному на фотографии лицу. Мы будем предполагать, что имеем дело с портретами, на которых есть ровно одно лицо, поэтому res[0] даст нам соответствующую информацию:
{'face_rectangle': <azure.cognitiveservices.vision.face.models._models_py3.FaceRectangle object at 0x7f72f23570b8>, 'additional_properties': {}, 'face_attributes': None, 'face_id': '59dc97ef-b5e2-4c83-99c0-75cdb69048fa', 'face_landmarks': <azure.cognitiveservices.vision.face.models._models_py3.FaceLandmarks object at 0x7f72f2357080>, 'recognition_model': None}
Поскольку в Python удобнее оперировать со словарями, мы можем получить все атрибуты проанализированного лица с помощью res[0].facial_landmarks.as_dict():
{'nose_left_alar_top': {'y': 147.4, 'x': 131.9}, 'eyebrow_right_inner': {'y': 106.3, 'x': 157.2}, 'pupil_right': {'y': 118.9, 'x': 170.9}, 'eye_right_outer': {'y': 118.5, 'x': 181.5}, 'pupil_left': {'y': 126.7, 'x': 112.6}, 'eyebrow_right_outer': {'y': 106.6, 'x': 192.1}, 'eye_right_top': {'y': 115.0, 'x': 171.3}, 'nose_tip': {'y': 158.4, 'x': 148.7}, 'upper_lip_top': {'y': 173.6, 'x': 150.3}, 'eyebrow_left_outer': {'y': 120.3, 'x': 84.1}, 'nose_right_alar_top': {'y': 143.8, 'x': 158.4}, 'nose_root_right': {'y': 124.3, 'x': 151.5}, 'nose_root_left': {'y': 126.3, 'x': 135.4}, 'eye_left_inner': {'y': 126.7, 'x': 122.4}, 'eyebrow_left_inner': {'y': 110.1, 'x': 122.9}, 'nose_left_alar_out_tip': {'y': 159.3, 'x': 128.2}, 'eye_left_outer': {'y': 128.9, 'x': 103.3}, 'eye_left_bottom': {'y': 131.4, 'x': 113.7}, 'eye_left_top': {'y': 122.8, 'x': 112.3}, 'eye_right_bottom': {'y': 123.5, 'x': 172.7}, 'under_lip_bottom': {'y': 193.0, 'x': 154.5}, 'under_lip_top': {'y': 186.2, 'x': 152.7}, 'upper_lip_bottom': {'y': 176.9, 'x': 151.7}, 'nose_right_alar_out_tip': {'y': 153.0, 'x': 167.0}, 'mouth_left': {'y': 182.6, 'x': 121.6}, 'mouth_right': {'y': 172.1, 'x': 177.8}, 'eye_right_inner': {'y': 120.8, 'x': 162.7}}
Загружаем изображения
К этому времени нам потребуется набор картинок. Я рекомендую для начала взять 15-20 своих портретных фотографий неплохого качества. Однако если Вам совсем лень искать фотографии, Вы можете взять готовые изображения Билла Гейтса, полученные с помощью Bing Image Search. Поместим их в директорию images:
mkdir images
wget https://github.com/shwars/NeuroWorkshopData/raw/master/Data/Gates50.zip
unzip -q Gates50.zip -d images
rm Gates50.zip
Если Вы используете Azure Notebook и хотите взять свои фотографии — создайте в Вашем проекте директорию images и загрузите туда фотографии вручную из начальной странички проекта.
Начинаем веселье! Загрузим все изображения, а также вызовем Face API для получения всех опорных точек:
import glob
filenames = []
images = []
imagepoints = []
for fn in glob.glob("images/*"):
print("Processing {}".format(fn))
with open(fn,'rb') as f:
res = cli.face.detect_with_stream(f,return_face_landmarks=True)
if len(res)>0:
filenames.append(fn)
images.append(cv2.cvtColor(cv2.imread(fn),cv2.COLOR_BGR2RGB))
imagepoints.append(res[0].face_landmarks.as_dict())
Для наглядности, нанесём опорные точки поверх изображения какой-нибудь случайной картинки:
def decorate(i):
img = images[i].copy()
for k,v in imagepoints[i].items():
cv2.circle(img,(int(v['x']),int(v['y'])),7,(255,255,0),5)
return img
display_images([decorate(i) for i in range(1,5)])
Здесь я использую функцию display_images для того, чтобы показать на экране список из картинок. Эта функция нам потребуется и дальше. Я для краткости не буду приводить здесь код, а отошлю Вас к репозиторию.

Аффинные преобразования
После получения опорных точек для всех фотографий, нам нужно выровнять их таким образом, чтобы все глаза на всех фотографиях находились в одних и тех же координатах. Для этого придётся масштабировать, поворачивать и растягивать изображения — иными словами, применять к ним аффинные преобразования. Известно, что аффинное преобразование целиком определяется тремя точками, точнее, происходящими с ними изменениями.
В нашем случае у нас есть координаты двух глаз, которые мы хотим переместить в точки с координатами (130,120) и (170,120) – эти координаты подобраны на глаз, если мы хотим получить целевое изображение размером 300x300 пикселей. Но для полноценного описания преобразования нам нужна ещё одна точка!
В качестве такой точки можно взять, например, середину рта – поскольку она в некотором роде находится напротив глаз, и образованный этими точками треугольник более менее полностью покрывает лицо. У нас нет готовых координат середины рта, но мы можем их посчитать, взяв среднюю точку между mouth_left и mouth_right.
Аффинное преобразование определяется матрицей. Функция getAffineTransform в OpenCV вычисляет эту матрицу по координатам трех точек до и после трансформации. Затем мы используем warpAffine для применения преобразования к изображению — эта функция также обрезает картинку до указанных размеров.
target_triangle = np.float32([[130.0,120.0],[170.0,120.0],[150.0,160.0]])
size = 300
def affine_transform(img,attrs):
mc_x = (attrs['mouth_left']['x']+attrs['mouth_right']['x'])/2.0
mc_y = (attrs['mouth_left']['y']+attrs['mouth_right']['y'])/2.0
tr = cv2.getAffineTransform(np.float32(
[(attrs['pupil_left']['x'],attrs['pupil_left']['y']),
(attrs['pupil_right']['x'],attrs['pupil_right']['y']),
(mc_x,mc_y)]), target_triangle)
return cv2.warpAffine(img,tr,(size,size))
Определив эту функцию, мы можем преобразовать все наши картинки:
img_aligned = [affine_transform(i,a) for i,a in zip(images,imagepoints)]
display_images(img_aligned[:5])

Вуаля!
Для получения финальной картинки нам осталось смешать все изображения вместе. Это делается простым усреднением всех numpy-массивов:
imgs=np.array(img_aligned,dtype=np.float32)/255.
plt.imshow(np.average(imgs,axis=0))
Здесь мы тем не менее применяем одну хитрость — приводим тип элементов массива к float32, чтобы потом их правильно усреднить. В противном случае могут возникнуть сложности с делением :)

А теперь – пробуем сами!
Теперь у вас есть всё необходимое, чтобы начать создавать свои замечательные портреты! Полный код с примером есть в репозитории на GitHub, при этом даже не обязательно устанавливать Python, поскольку можно использовать Azure Notebooks прямо из браузера. Поэтому нет никаких оправданий, чтобы не попробовать самому!
Чтобы дать вам ещё одну причину попробовать (кроме любопытства и креативности), я от себя лично подарю свою книжку по F# за лучшее произведение в жанре PeopleBlending (самовывозом, или почтой России)! Оставляйте ссылки на работы (а лучше на посты в социальных сетях) в комментариях, или присылайте мне до 1 января. Оставляю за собой право опубликовать лучшие работы в блоге.
Кстати, не обязательно ограничивать себя наложением фотографий! Подумайте, какие креативные сценарии использования опорных точек лица вы сможете придумать, и воплощайте идеи в реальность!
Всем творческих успехов!