В предыдущем посте про Azure Machine Learning я рассказал, как можно легко начать использовать Azure ML с помощью Visual Studio Code. Мы продолжим рассматривать начатый пример про обучение модели классификации рукописных цифр на наборе данных MNIST.
Автоматизация экспериментов с Azure ML Python SDK
Для оптимизации гиперпараметров нам необходимо провести множество экспериментов, отличающихся значениями параметров. Мы уже знаем, что Azure ML позволяет нам автоматически отслеживать и аккумулировать в одном месте результаты всех экспериментов. Поэтому самое простое, что мы можем сделать для оптимизации гиперпараметров – это научиться автоматически запускать эксперименты, перебирая параметры из допустимого диапазона.
Вместо запуска экспериментов из VS Code, мы будем использовать Azure ML Python SDK. Все операции — начиная от создания кластера, конфигурации эксперимента и получения результатов – могут быть проделаны с помощью нескольких строчек кода на Python. Поначалу этот код может показаться слегка сложноватым, но стоит вам пройти этот путь хотя бы раз — и вы поймёте, как Azure ML упрощает процесс!
Запускаем код
Код, о котором говорится в этой статье, доступен в репозитории Azure ML Starter. Основной файл, на который мы будем смотреть — это ноутбук submit.ipynb. Вы можете запускать его одним из нескольких способов:
- Если у вас настроено локальное Python-окружение с Jupyter, то вы можете запустить ноутбук локально, выполнив команду
jupyter notebook в директории с файлом submit.ipynb. В этом случае вам необходимо будет предварительно установить Azure ML SDK, запустив в консоли pip install azureml-sdk - Загрузив ноутбук в разделе Notebook на Azure ML Portal и запустив его оттуда. При этом вам потребуется создать и запустить виртуальную машину для ноутбуков внутри Azure ML Workspace.
- Используя Azure Notebooks
Если вы предпочитаете старые добрые Python-файлы ноутбукам, то тот же самый код доступен в файле submit.py.
Подключаемся к Azure ML Workspace и к кластеру
Первое, что необходимо сделать при работе с Azure ML – подключиться к Azure ML Workspace. Для этого необходимо знать subscription id, имя workspace, и имя ресурсной группы подробнее на Microsoft Docs:
ws = Workspace(subscription_id,resource_group,workspace_name)
Можно указать эти данные вручную, но ещё проще – это поместить все данные в файл под названием config.json, расположенный в текущей директории, что позволит нам создать ссылку на Workspace одной командой:
ws = Workspace.from_config()
Сам файл config.json со всем данными для подключения можно скачать с Azure Portal, перейдя на страничку Azure ML Workspace:
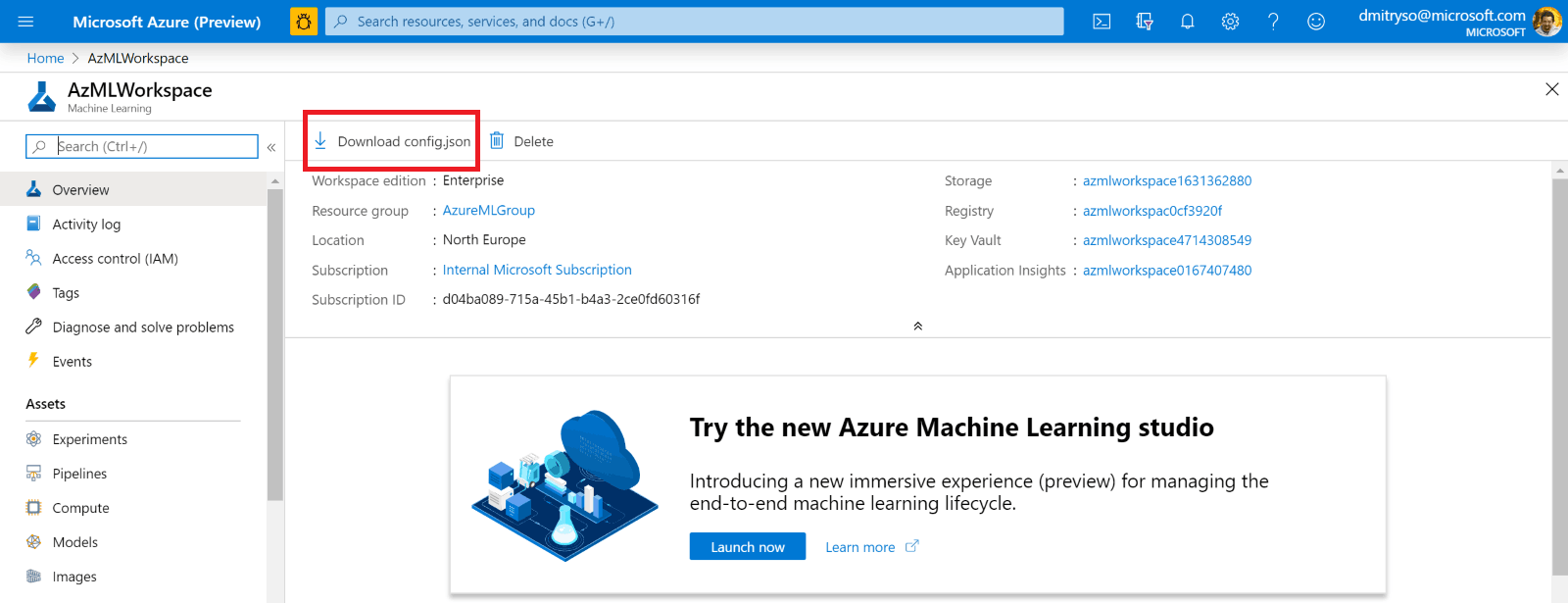
Поключившись к Workspace, мы теперь можем получить ссылку на вычислительный кластер с помощью простого вызова:
cluster_name = "AzMLCompute"
cluster = ComputeTarget(workspace=ws, name=cluster_name)
При этом мы подразумеваем, что вы уже создали кластер по имени AzMLCompute вручную, как описано в предыдущем посте. Если нет — вы можете также создать кластер программным путём, соответствующий код приведён в файле submit.ipynb.
Готовим и загружаем датасет
В примере из предыдущего поста мы загружали данные MNIST из репозитория OpenML в начале эксперимента. Если же мы хотим повторять эксперимент многократно, то имеет смысл загрузить данные один раз и сохранить их “поближе” к вычислительному кластеру — внутри Azure ML Workspace.
Для начала, создадим папку dataset и поместим туда данные. Для этого выполните в консоли файл [create_dataset.py](https://github.com/CloudAdvocacy/AzureMLStarter/blob/master/create_dataset.py), он скачает данные с OpenML и запишет в сериализованном виде в директорию dataset.
С каждым Azure ML Workspace связывается хранилище данных по умолчанию. Чтобы загрузить туда наши данные, выполним следующую команду (в нашем случае в рамках submit.ipynb):
ds = ws.get_default_datastore()
ds.upload('./dataset', target_path='mnist_data')
Запускаем эксперименты
На этот раз мы будем обучать чуть более сложную (но по-прежнему не оптимальную) модель распознавания цифр на основе двухслойной полносвязной сети с использованием фреймворка Keras. Соответствующий файл для обучения модели называется train_keras.py. Он принимает на вход ряд параметров командной строки, с помощью которых можно устанавливать разные значения гиперпараметров:
--data_folder – путь к файлам с данными--batch_size – размер minibatch (по умолчанию 128)--hidden – число нейронов в скрытом слое (по умолчанию 100)--dropout – используемый коэффициент dropout
Чтобы подать эксперимент с некоторыми значениями параметров, мы сначала задаём параметры скрипта, а затем создаём объект Estimator, который представляет собой скрипт вместе с конфигурацией для его запуска (параметрами и окружением):
script_params = {
'--data_folder': ws.get_default_datastore(),
'--hidden': 100
}
est = Estimator(source_directory='.',
script_params=script_params,
compute_target=cluster,
entry_script='train_keras.py',
pip_packages=['keras','tensorflow'])
В нашем случае мы передаём только число нейронов скрытого слоя, но можно аналогичным образом передавать и другие гиперпараметры. Также мы указываем, какие пакеты pip (или conda) необходимо установить в нашем окружении.
Чтобы запустить эксперимент, мы выполним следующие строки:
exp = Experiment(workspace=ws, name='Keras-Train')
run = exp.submit(est)
Следить за ходом эксперимента можно, распечатав значение переменной run (это особенно удобно, если у вас установлены Jupyter-расширения azureml.widgets), или же с портала Azure ML: 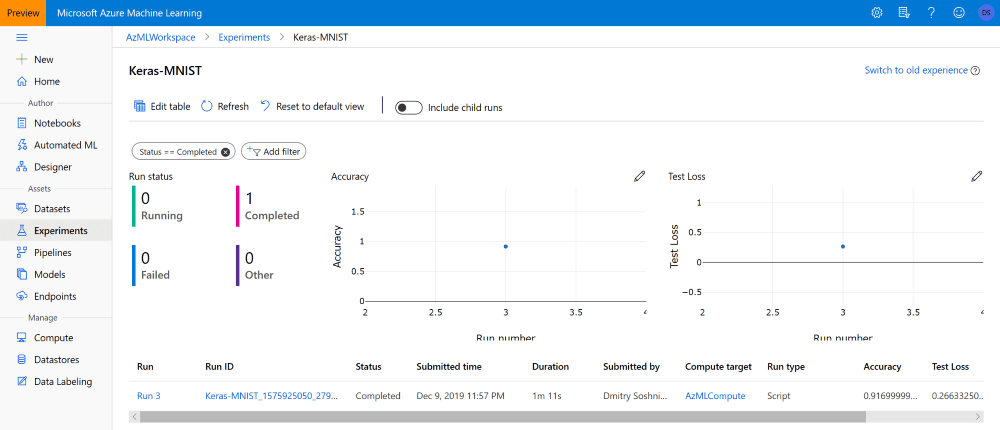
Оптимизация гиперпараметров с HyperDrive
Для перебора гиперпараметров и поиска оптимальной комбинации необходимо совершить перебор параметров, т.е. запустить множество экспериментов с разными значениями и сравнить результаты. Это можно сделать с использованием описанного подхода, но ещё лучше использовать специально разработанную для этого технологию Hyperdrive.
При этом нам необходимо определить пространство перебора гиперпараметров, и алгоритм выбора, которые описывает, как комбинации гиперпараметров будут выбираться из этого пространства:
param_sampling = RandomParameterSampling({
'--hidden': choice([50,100,200,300]),
'--batch_size': choice([64,128]),
'--epochs': choice([5,10,50]),
'--dropout': choice([0.5,0.8,1])})
В нашем примере мы описываем пространство как множество возможных значений (choice), однако можно использовать также интервалы вещественных чисел с различным распредлением вероятности (uniform, normal и т.д. – подробнее описано тут). Помимо алгоритма случайного выбора (Random Sampling), можно использовать также Grid Sampling (полный перебор) или Bayesian Sampling.
В дополнение к этому, мы можем определить Early Termination Policy. Если скрипт сообщает достигнутые значения точности в процессе своего выполнения (с помощью вызовов run.log), то мы можем завершить его выполнение досрочно в том случае, если достигнутая точность растёт медленнее, чем средняя:
early_termination_policy = MedianStoppingPolicy()
hd_config = HyperDriveConfig(estimator=est,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
primary_metric_name='Accuracy',
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=16,
max_concurrent_runs=4)
Определив все параметры эксперимента Hyperdrive, мы запускаем его выполнение на кластере:
experiment = Experiment(workspace=ws, name='keras-hyperdrive')
hyperdrive_run = experiment.submit(hd_config)
В портале Azure ML, эксперимент по оптимизации гиперпараметров представлен одной строчкой (родительским экспериментов). Чтобы посмотреть результаты дочерних экспериментов, необходимо выбрать пункт include child runs: 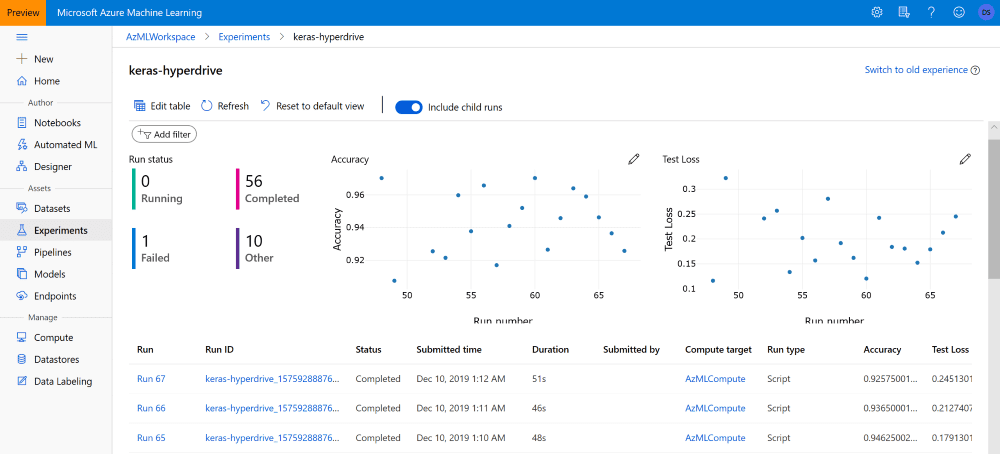
Выбираем лучшую модель
После того, как эксперимент Hyperdrive завершился, мы можем вручную выбрать лучшую модель на Azure ML Portal. В нашем скрипте train_keras.py после обучения модели мы записывали её сериализованное представление в папку outputs:
hist = model.fit(...)
os.makedirs('outputs',exist_ok=True)
model.save('outputs/mnist_model.hdf5')
Это значит, что теперь с каждым запуском эксперимента ассоциирован свой файл mnist_model.hdf5, который мы можем найти и загрузить на Azure ML Portal: 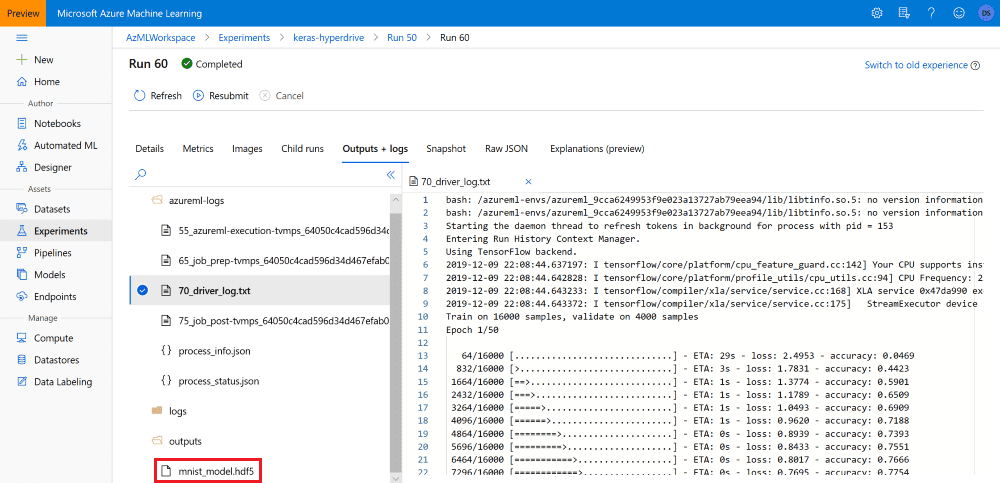
Мы также можем использовать сервис управления моделями Azure ML чтобы зарегистрировать лучшую модель и использовать её потом для развертывания в Azure ML. Это можно сделать программным путём с помощью Python SDK:
best_run = hyperdrive_run.get_best_run_by_primary_metric()
best_run_metrics = best_run.get_metrics()
print('Best accuracy: {}'.format(best_run_metrics['Accuracy']))
best_run.register_model(model_name='mnist_keras',
model_path='outputs/mnist_model.hdf5')
Выводы
Мы научились программным образом запускать эксперименты Azure ML, а также запускать множество экспериментов для оптимизации гиперпараметров с технологией Hyperdrive. Хотя требуется немного усилий, чтобы привыкнуть к этому процессу, но через некоторое время вы поймёте, что автоматический перебор гипераметров с Azure ML намного проще, чем проведение серии экспериментов вручную на виртуальных машинах DSVM.
Ссылки