Технологии искусственного интеллекта и анализа данных всё стремительнее входят в нашу жизнь, и они могут дать еще один шанс решению действительно важных для людей социальных задач, которые ранее не были реализованы. С этой целью центр цифрового развития АСИ организовал конкурс World AI & Data Challenge, цель которого - структурировать процесс поиска социальных задач и их решений.
О конкурсе
Это не классический хакатон, где командам за два дня необходимо создать летающий корабль. Конкурс длится год и разделен на три этапа.
На первом этапе представители региональных органов власти и сообществ ставят наиболее актуальные для них задачи и, по возможности, находят соответствующие датасеты. После сбора всех задач подключаются эксперты конкурса, чтобы провести акселерацию задач, а также оценить их на соответствие требованиям конкурса и наличие данных для перехода лучших на следующий этап. Всего поступило 147 задач от 43 регионов России, а также из Сингапура, Казахстана, Узбекистана и Монголии. По итогам голосования осталось 30 задач из 30 регионов, в том числе 8 из них - задачи международного уровня.
Сейчас идет второй этап конкурса, где разработчики со всего мира находят решения отобранных задач. На сегодняшний день к проекту подключилось уже более 2 тысяч ребят. Каждый участник берет наиболее близкую ему тему: кто-то хочет спрогнозировать потребность медицинских организаций в лекарствах, кто-то разрабатывает сервис по выявлению факта развития сердечно-сосудистых заболеваний, а некоторые берутся решать более глобальную задачу по снижению бедности в мире. Полный список задач для решений можете посмотреть здесь. Главное - успеть загрузить свои проекты на платформу http://git.asi.ru до 31 августа 2020 г..
Главное отличие конкурса от других классических соревнований кроется в третьем этапе (сентябрь - февраль 2021 г.), на котором лучшие разработанные решения внедряются в реальную жизнь совместно с постановщиками задач и при поддержке АСИ. Лучшие решения также будут представлены для тиражирования по России и в другие страны. Именно на этом этапе решения вступают в режим опытной эксплуатации и могут быть серьезно переработаны.
Призовой фонд проекта будет пополняться, на данный момент он составляет 1,5 млн рублей. Помимо этого, победителям предусмотрены гранты на вычислительные мощности от 1 млн и курсы по Data Science от лучших мировых онлайн-школ.
Распознавание шрифта Брайля
Одна из наиболее интересных мне задач в этом конкурсе - это распознавание шрифта Брайля. В идеале в результате решения должен быть создан продукт, который преобразует документ на языке Брайля, снятый на камеру смартфона или отсканированный на сканере, в текст.
Несмотря на кажущуюся простоту задачи, она осложняется рядом моментов:
- Шрифт Брайля пропечатывается с помощью выпуклостей на бумаге, и поэтому при фотографировании не очень хорошо виден
- Некоторые книги используют двухстороннюю печать, и распознавание таких текстов также представляет интерес
Из позитивных моментов - шрифт Брайля достаточно хорошо формализован, и в принципе распознавание отдельных букв может быть алгоритмизировано и запрограммировано.
Смотрим на существующие решения
Для начала, немного поизучаем, что уже сделано в направлении распознавание Брайля. Например, в 2017 году был вот такой пост, анонсировавший проект распознавателя на GitHub, но при внимательном изучении оказывается, что сам проект - это несколько скриптов на Python (из которых, тем не менее, можно будет взять какой-то код для вдохновения). При внимательном поиске находится ещё пара проектов, которые примерно в таком же состоянии, например вот такой. Явно есть над чем поработать!
Также имеет смысл поискать научные статьи на тему, например к упомянутому выше проекту есть вот такая статья. Ещё пара интересных статей: Smart Braille System Recognizer (2013), или совсем современная статья этого года Optical Braille Recognition Based on Semantic Segmentation Network.
Искать лучше всего на английском языке, поскольку количество международных публикаций сильно больше специализированных русскоязычных. Найти что-то разумное про распознавание русского языка мне не удалось, хотя есть неплохой tutorial про распознавание Брайля на сербском
Изучаем датасет и ищем дополнительные данные
Вместе с задачей предлагается вот такой датасет, который содержит изображения, но в них отсутствует соответствующий текстовый эквивалент. Вот как выглядит фрагмент текста, который необходимо научиться распознавать:

Там же есть ещё датасет для двухсторонней печати, но на китайском языке.
Для решения задачи классификации нам потребуется также датасет, который бы устанавливал соответствие изображения и текста, поэтому попробуем поискать какие-то внешние датасеты:
- Разумный датасет для распознавание отдельных символов находится на Kaggle, он содержит фотографии отдельный символов Брайля, к которым применены различные трансформации, вроде поворота или изменения яркости. На таком датасете в принципе можно обучить распознаватель отдельных символов.
- В упомянутом выше проекте на GitHub находится неплохой датасет символов, полученных фотографированием реальных книг, с последующим применением преобразований для data augmentation.
- Поскольку алфавит азбуки Брайля известен, теоретически возможно попытаться сгенерировать искусственный датасет на основе произвольных текстов. При этом важно научиться делать это так, чтобы изображения выглядели достаточно реалистично, т.е. предусмотреть различные варианты освещения, поворота, диаметров точек и т.д.

Общая архитектура решения
В целом, задачу распознавания текста по фотографии страницы можно разбить на следующие этапы:
- Предварительная обработка фотографии с целью нормализации яркости/контраста
- Выделение границ текста, вырезание области с символами и (в идеале) исправление геометрических перспективных искажений
- Разбиение текста на отдельные символы
- Распознавание отдельных символов, с помощью нейросети или алгоритмически
- Коррекция полученного текста с целью исправления единичных ошибок. Для этого, в простейшем случае, может использоваться обычный spell checker, например, имеющийся к наборе когнитивных сервисов Microsoft.
Давайте кратко рассмотрим эти пункты. Код, который я буду здесь демонстрировать, есть на GitHub в репозитории https://github.com/shwars/braillehack. Если вы будете использовать его на хакатоне - делайте fork! Запустить и посмотреть работу кода вы можете с помощью Visual Studio Codespaces
Предобработка изображений
Для работы с изображениями мы будет использовать OpenCV. Для начала, считываем один из файлов из нашего датасета и сразу преобразуем его к чёрно-белому изображению:
im = cv2.imread('../data/Photo_Turlom_C1_2.jpeg')
im = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)

Изображение выглядит зелёным, поскольку по умолчанию изображения показываются в цветовом диапазоне от синего до зелёного. Чрезмерная зелёность говорит о том, что исходное изображение сильно засвечено, и чёрных тонов в нём мало. Это и неудивительно: шрифт Брайля - это по сути дела белая бумага с небольшими углублениями.
Далее применяем ряд преобразований, чтобы получить хорошее контрастное изображение самих точек:
im = cv2.blur(im,(3,3))
im = cv2.adaptiveThreshold(im, 255, cv2.ADAPTIVE_THRESH_MEAN_C,
cv2.THRESH_BINARY_INV, 5, 4)
im = cv2.medianBlur(im, 3)
_,im = cv2.threshold(im, 0, 255, cv2.THRESH_OTSU)
im = cv2.GaussianBlur(im, (3,3), 0)
_,im = cv2.threshold(im, 0, 255, cv2.THRESH_OTSU)
plt.imshow(im)
В результате из нашего исходного изображения получаем следующее: 
Получаем координаты точек
Для правильного вырезания области с символами нам необходимо определить границы текста, и затем применить к тексту некоторое преобразование, удаляющее искажения перспективы. Хорошо процесс выравнивания изображений описан в этой статье.
Для нахождения крайних точек текста для начала выделим из картинки ключевые точки. Для этого используются так называемые feature detectors, и в составе OpenCV реализован детектор ORB, который может быть реализован парой строк кода:
orb = cv2.ORB_create(5000)
f,d = orb.detectAndCompute(im,None)
5000 - это максимальное число ключевых точек, которые мы хотим искать. Если мы теперь построим эти точки на пустом изображении то увидим, что все наши точки из символов алфавита были обнаружены:
def plot_dots(im,dots):
img = np.zeros_like(im)
for x in dots:
cv2.circle(img,(int(x[0]),int(x[1])),1,(255,0,0))
plt.imshow(img)
pts = [x.pt for x in f]
plot_dots(cim,pts)

Два подхода к решению задачи
Получив множество точек Брайля на исходном изображении, мы можем идти двумя путями:
- Рассматривать задачу распознавания шрифта Брайля как классическую задачу классификации для компьютерного зрения. В этом случае нам предстоит разбить текст на символы, и потом применить свёрточную нейросеть для решения задачи классификации. Полученные координаты точек мы будет использовать лишь для выделения фрагмента изображения, содержащего символы, для последующего разбиения текста на символы.
- Использовать полученные координаты точек для решения задачи алгоритмически.
Использование feature detector позволило нам свести задачу работы с изображением к множеству точек, с которыми мы можем работать алгоритмически.
Здесь важно отметить один момент: одной точке на изображении возможно соответствует несколько обнаруженных ORВ-алгоритмом ключевых точек, о чем свидетельствует разная яркость точек на полученном изображении. Если мы хотим использовать алгоритмическое распознавание, нам скорее всего понадобится отсеять близко лежащие точки - вот тут обсуждают, как это можно сделать более менее эффективно.
Мы не будем рассматривать алгоритмический способ решения, но он кажется достаточно привлекательной альтернативой! Надеюсь, какая-то из работающих над этой задачей команд пойдёт по этому пути!
Вырезание области с символами
Для применения классического распознавания символов, нам потребуется вырезать область с символами, чётко расположив её внутри прямоугольника, убрав лишние поля и (в идеале) искажения перспективы. Для этого мы воспользуемся гомотопным преобразованием, для задания которого необходимо указать трансформацию четырех точек. В качестве первого приближения, давайте возьмем минимальные и максимальные координаты точек из нашего множества, и рассмотрим соответствующий прямоугольник. Для более “правильного” преобразования, и чтобы учесть перспективу, вам нужно будет придумать более мудрый алгоритм поиска крайних точек:
min_x, min_y, max_x, max_y = \
[int(f([z[i] for z in pts]))
for f in (min,max) for i in (0,1)]
Далее приведём построенный нами прямоугольник к прямоугольнику с заданной длиной сторон (например, 500):
off = 5
src_pts = np.array([(min_x-off,min_y-off),(min_x-off,max_y+off),
(max_x+off,min_y-off),(max_x+off,max_y+off)])
dim = 500
dst_pts = np.array([(0,0),(0,dim),(dim,0),(dim,dim)])
h,m = cv2.findHomography(src_pts,dst_pts)
trim = cv2.warpPerspective(cim,h,(dim,dim))
plt.imshow(trim)

Мы получили практически идеальный прямоугольник с текстом.
Разбиваем текст на символы
Для разбиения текста на символы мы воспользуемся тем фактом, что каждый символ занимает на картинке одинаковое место, и просто разобьем картинку на прямоугольники меньшего размера.
char_h = 32
char_w = 22
def slice(img):
dy,dx = img.shape
y = 0
while y+char_h<dy:
x=0
while x+char_w<dx:
# Корректируем сдвиг по x
while np.max(img[y:y+char_h,x])!=0:
x+=1
while np.max(img[y:y+char_h,x+char_w])!=0:
x-=1
# Пропускаем полностью пустые символы
if np.max(img[y:y+char_h,x:x+char_w])>0:
yield img[y:y+char_h,x:x+char_w]
x+=char_w
y+=char_h
sliced = list(slice(trim))
Здесь мы используем одну хитрость. Из-за неточностей арифметики возможны смещения, которые могут накапливаться и привести к тому, что разрез “заедет” на границу символа. Поэтому в том случае, если граница символа содержит какие-то точки, мы слегка корректируем координату x. Аналогичный приём можно попытаться применить для вертикального разбиения на строки.
В результате применения процедуры разрезания к нашему набору, получаем следующий результат:
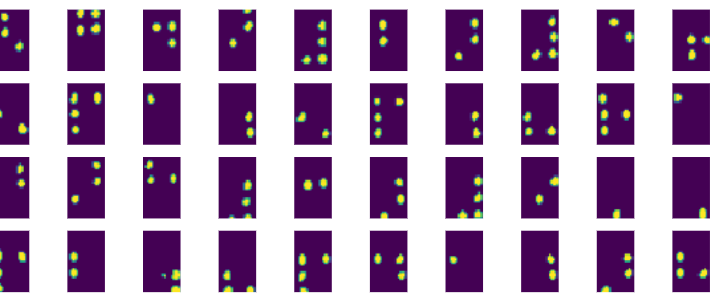
Свёрточная сеть для распознавания символов
Я не буду подробно останавливаться на том, как происходит процесс обучения свёрточной сети для распознавания символов, поскольку этот процесс очень похож на распознавание рукописных цифр в датасете MNIST, про который написано множество обучающих текстов, например:
Финальная коррекция текста
После посимвольного распознавания картинки, мы получим на выходе текст. Из-за неточностей распознавания, он может содержать ошибки в некоторых символах. Например, недостаточно пропечатанная точка в каком-то месте скорее всего приведёт к тому, что буква будет распознана неверно.
Уменьшить количество таких ошибок возможно, используя семантическую коррецию текста. Поскольку мы ожидаем, что на вход подаётся осмысленный текст, а не случайный набор букв, то применение стандартной процедуры проверки орфографии должно исправлять некоторые такие ошибки. Для этого проще всего использовать готовую предобученную модель, входящую в состав
когнитивных сервисов Microsoft, поскольку для этого достаточно будет сделать один REST-вызов. На хакатоне и при разработке MVP лучше все типовые задачи поручать готовым сервисам для экономии времени.
Создание приложения
К этому моменту мы получили модель (в виде некоторого кода или функции на языке Python), способную по входной фотографии вернуть распознанный текст. Однако в задании сказано, что в результате конкурса ожидается приложение, а не только работающая модель. Поэтому будет правильным потратить немного времени и оформить всё в виде конечного работоспособного продукта (MVP), благо облачные технологии Microsoft Azure позволяют сделать это весьма безболезненно.
В качестве клиенской части приложения можно использовать:
- Чат-бот в Telegram или Skype, который будет получать на вход фотографию. Реализация чат-ботов максимально просто делается с помощью Microsoft Bot Framework.
- Мобильное приложение, по возможности кросс-платформенное, для создания которого можно использовать Xamarin или React Native
- Веб-сайт
Основную процедуру распознавания в виде кода на Python удобнее всего выполнять на сервере, в виде облачного REST-сервиса. По сути речь идёт про создание веб-API, которым будет пользоваться ваше клиентское приложение. Такое API лучше всего оформить в виде Azure Function с HTTP-триггером.
Azure Function – это по сути фрагмент кода на каком-то языке программирования (в нашем случае на Python), который срабатывает при наступлении какого-то события (в нашем случае - при вызове REST-запроса). Подбробнее о том, как создать такую функцию с использованием Python - читайте в этом руководстве.
Очень похожий по архитектуре клиент-серверный проект виртуального музейного экспоната я описал в своей статье. Фрагментами кода оттуда тоже можно вдохновляться!
Выводы
В этой статье я постарался кратко описать процесс решения задачи распознавания шрифта Брайля, от поиска существующих решений, до выбора метода решения задачи, построения модели и оформления всего проекта в виде готового MVP-прототипа. Я старался не только приводить фрагменты решения, но и показать процесс рассуждений и поиска путей, который может быть применён для решения других задач этого или другого аналогичного конкурса.
Работоспособный пример кода, описанного в данной статье, вы можете найти на http://github.com/shwars/braillehack. Он, в некотором смысле, “обрывается на полуслове” - в основном для того, чтобы вы могли оттолкнуться от него и доработать своё решение. Если у вас будут возникать вопросы, или если получится сделать что-то работающее на основе этого кода - пишите мне, координаты есть на сайте http://soshnikov.com.
Удачного конкурса! Надеемся, что кому-то из участников удастся сделать действительно хорошее решение, которое будет исключительно полезно, поскольку поможет расширить возможности общения учителей, родственников слепых и слабовидящих детей и упростит проверку домашних работ ребенка из-за отсутствия навыков чтения шрифта Брайля.